Leadership through Crisis: Decision-Making When the Stakes Are High
This course is built for people who have been in the room when things go wrong — and who want to be better prepared next time. It is not a theoretical survey of crisis management literature. It is a structured, evidence-…
Not Every Emergency Is a Crisis
Most organisations confuse emergencies with crises, and that confusion kills people. This opening chapter draws a hard, consequential line between incidents, emergencies, and genuine crises — and explains why the…
Five small disasters at once vs. one huge disaster — which would actually stress you out more?
Which is worse
Would you rather face a guaranteed disaster tomorrow or spend the next month not knowing if something bad will happen?
Would you rather
What's something you consider a total crisis but your friends think is just... Tuesday?
Your crisis confessions
When you have NO clue what's happening in a situation, do you freeze up, ask a million questions, or just wing it?
Your chaos move
Is freaking out over nothing worse than staying weirdly calm during an actual emergency?
Debate time
You're getting completely different information from multiple people about the same urgent problem. Who do you believe?
Real talk
Crisis Triage Tournament
15 minutesEach table receives 6-8 scenario cards (e.g., 'hospital power outage,' 'CEO scandal,' 'data breach,' 'natural disaster'). Teams have 3 minutes to sort them into CRISIS, EMERGENCY, or INCIDENT using Boin et al.'s framework (threat, urgency, uncertainty). After sorting, instructor polls one scenario at a time. Teams hold up colored cards (red=crisis, yellow=emergency, blue=incident). Instructor reveals the distribution, then calls on opposing teams to defend their classifications. Teams earn points for well-justified answers, not 'correct' ones.
Swiss Cheese Autopsy
12-15 minutesEach table receives a famous failure case (e.g., Challenger disaster, BP Deepwater Horizon, COVID-19 response lag) and 5-6 blank 'cheese slice' cards. Teams have 7 minutes to identify defensive layers that existed (organizational, technological, human) and the 'holes' that aligned to allow failure. They physically arrange cards to show the model. Tables then do a 90-second gallery walk to view other teams' models. Reconvene for 3-4 tables to share their most surprising 'hole.'
Sensemaking Breakdown Simulation
10 minutesInstructor announces: 'Breaking news: Reports of explosion at campus building.' Each table becomes a different stakeholder group (campus police, PR team, facilities, student government, media, administration). Teams receive incomplete, contradictory information cards delivered in waves every 90 seconds. They must make decisions with uncertain info. After 6 minutes, stop the simulation. Debrief: When did sensemaking collapse? What cues did they ignore? What plausibility narratives did they create? Connect to Weick's framework: identity, retrospect, enactment, social, ongoing, cues, plausibility.
Urgency-Uncertainty Matrix Mapping
8-10 minutesInstructor projects a 2x2 matrix (High/Low Urgency vs. High/Low Uncertainty). Each table gets 4-5 sticky notes with scenario names written on them. Teams have 4 minutes to place their scenarios on the matrix drawn on their table or large paper. Then teams rotate one seat clockwise to adjacent table and have 2 minutes to challenge or move ONE placement, writing their rationale. Original teams return and see changes. Quick whole-class poll: 'Which quadrant defines true CRISIS?' Discuss why high urgency + high uncertainty = crisis zone.
The 'Not a Crisis' Defense
12 minutesInstructor assigns each table a scenario widely considered a crisis (e.g., Flint water crisis, Facebook data scandal, Afghanistan withdrawal). Twist: Teams must argue it was NOT actually a crisis—just a badly managed emergency or incident. They have 5 minutes to build their argument using Boin's framework (maybe threat wasn't existential? Uncertainty was manageable?). Each table sends a spokesperson to present their 60-second defense. Class votes on most convincing argument. Debrief: What did this reveal about the fuzzy boundaries between categories?
Cascading Failure Chain Reaction
15 minutesEach table receives a simple starting incident (e.g., 'IT intern clicks phishing link'). Teams have 3 minutes to map out a realistic failure cascade: What hole in the next cheese slice allows it to progress? Write each failure stage on separate cards and arrange linearly. Then tables swap their chains with an adjacent table. New table has 3 minutes to identify where defensive layers COULD have stopped the cascade (add 'intervention cards' between stages). Finally, 2-3 tables present their intervention strategies. Discuss: How do small incidents become crises when defenses fail?
Transcript
At twelve fifty-four a.m. on June fourteenth, 2017, a resident of Flat sixteen on the fourth floor of Grenfell Tower in North Kensington, London, called the fire brigade to report a fire in his kitchen. It was, to every outward appearance, a routine incident — the sort of call the London Fire Brigade handles thousands of times each year. Firefighters arrived within six minutes. The initial incident commander treated it as exactly what it appeared to be: a single-flat fire in a high-rise building. Stay-put advice was given to residents, consistent with standard operating procedure.
Within thirty minutes, the building's exterior cladding had turned Grenfell Tower into a vertical chimney of flame. Seventy-two people would die. The stay-put policy that was correct for a contained flat fire became catastrophically wrong for what was actually happening. But the system was slow — agonizingly slow — to recognize that the situation had crossed a threshold. The question that would haunt every subsequent inquiry was not "Why did the fire spread?" but something more fundamental: Why did the people in charge keep treating a crisis as if it were a manageable emergency?
[short pause]
That question — the failure to recognize a crisis when one has begun — is where this course starts. Not with leadership techniques or communication frameworks or decision-making heuristics, but with the more primitive and consequential act of classification. Before you can lead through a crisis, you must be able to recognize that you are in one. And most organizations, most of the time, cannot.
This chapter draws a hard, consequential line between three categories of adverse events: incidents, emergencies, and crises. It introduces three foundational frameworks — Boin and colleagues' crisis characteristics, James Reason's Swiss Cheese model of systemic failure, and Karl Weick's sensemaking framework — that together explain how crises emerge, why they are different from other bad events, and why the human capacity to understand what is happening can collapse at precisely the moment it matters most.
[short pause]
Organizations face adverse events constantly. A server crashes. A patient falls. A delivery truck breaks down. Most of these events are absorbed by existing systems without requiring anything more than routine response. But the language we use to describe these events is often imprecise, and that imprecision has consequences.
Researchers have long noted the "definitional ambiguity" that plagues the field, as Samarasinghe and Hettiarachchi noted in 2016. The terms "incident," "emergency," "crisis," and "disaster" are frequently used interchangeably in both popular and professional discourse. A hospital administrator describes a staffing shortage as a "crisis." A news anchor calls a house fire an "emergency." A government spokesperson labels a political scandal a "disaster." Each usage feels intuitively reasonable. Each is, technically, wrong — and the confusion matters because the leadership response demanded by each category is fundamentally different.
An incident is an adverse event that falls within the routine capacity of existing systems and personnel. It may be unwelcome, even dangerous to the individuals immediately involved, but it does not overwhelm the organization's standard operating procedures. A construction worker cuts their hand. A fire alarm triggers in a building and is quickly traced to burnt toast. A quality control system catches a defective product batch before it ships. Each of these events activates a response, but the response is well-rehearsed, adequately resourced, and carried out within normal authority structures.
The key feature of an incident is that the gap between what is happening and what the organization is equipped to handle is essentially zero.
An emergency escalates the stakes. There is genuine threat — to life, property, or organizational continuity — and there is time pressure. But the defining feature that separates an emergency from a crisis is that the nature of the problem is understood. A chemical spill at an industrial facility is dangerous and urgent, but if the substance is known, the containment protocols are established, and the response teams are trained for this specific scenario, the situation remains an emergency. It demands more resources, higher authority, and faster action than a routine incident, but it does not demand a fundamentally different way of thinking.
Emergencies are, in a phrase, serious but solvable within existing frameworks. The leadership challenge is one of execution and coordination, not of comprehension.
[short pause]
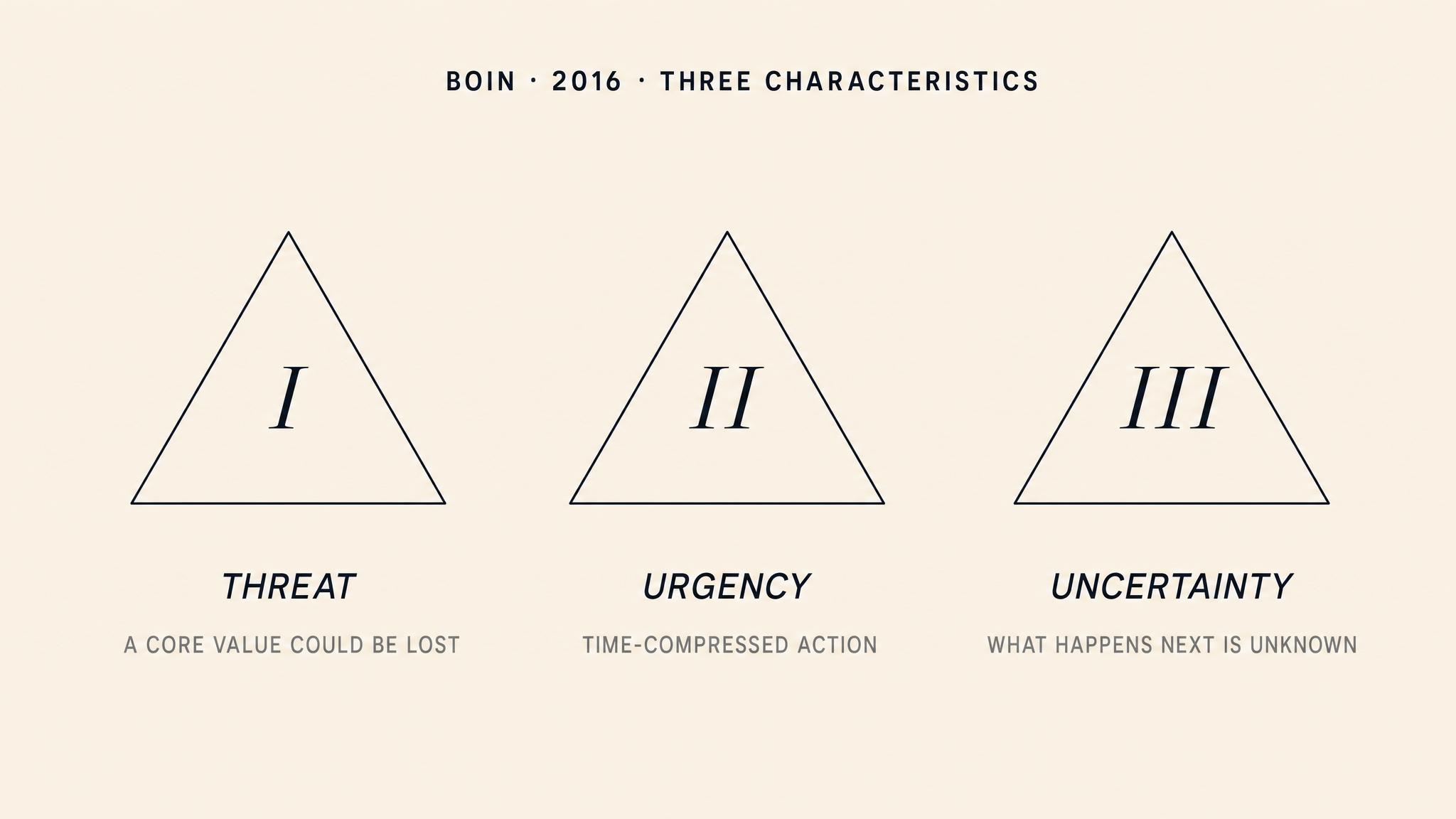
A crisis is categorically different. In their seminal work The Politics of Crisis Management, Boin, 't Hart, Stern, and Sundelius, in their 2005 work revised in 2016, define crisis through the simultaneous presence of three characteristics:
THREAT — to core values, life-sustaining systems, or critical infrastructure. Not a peripheral inconvenience but a challenge to something the community or organization holds fundamental.
URGENCY — severe time compression that demands immediate decision-making. The window for effective action is closing, and delay itself becomes a decision with consequences.
UNCERTAINTY — deep ambiguity about the nature of the threat, its trajectory, and the appropriateness of available responses. Leaders do not simply face a difficult problem; they face a problem they do not yet fully understand.
[short pause]
Crucially, Boin and colleagues argue that all three characteristics must be present simultaneously for a situation to constitute a genuine crisis. Remove any one, and the leadership challenge changes fundamentally. A situation with threat and urgency but no uncertainty is an emergency — serious and time-pressured, but manageable through known procedures. A situation with threat and uncertainty but no urgency allows for deliberation, consultation, and careful analysis. Only when all three converge does the organization face the distinctive challenge this course addresses: making consequential decisions under time pressure about a problem you do not fully understand.
This framework also illuminates an important dynamic: situations become crises. They travel what Boin and colleagues describe as a continuum from "no problem" to "deep crisis," and the transition can be gradual or shockingly abrupt. The Grenfell Tower fire began as an incident, passed through emergency, and crossed into crisis territory — but the command structure continued operating in emergency mode long after the threshold had been crossed.
Consider the last time your organization — workplace, university, or community group — faced a significant adverse event. Which of Boin's three criteria were present? Which were absent? How would you classify the event — and did the leadership response match the actual classification, or the perceived one?
[short pause]
If crises are defined by the convergence of threat, urgency, and uncertainty, the next question is: where do they come from? The answer, almost without exception, is not "a single catastrophic failure." It is the quiet, incremental accumulation of weaknesses across an entire system.
James Reason's Swiss Cheese model, described in 1997, provides the most influential framework for understanding this dynamic. Reason observed that organizations build multiple layers of defense against hazards — policies, training programs, supervision structures, safety equipment, procedural checklists, regulatory oversight. Each layer is designed to catch failures that slip through the layers above it. In theory, these defenses make catastrophic failure impossible. In practice, every layer has weaknesses — holes, like the holes in slices of Swiss cheese.
These holes come in two forms. Active failures are the unsafe acts committed by individuals at the sharp end of the system — the pilot who misreads an instrument, the nurse who administers the wrong dosage, the firefighter who misjudges a situation. These are the failures that are most visible and most frequently blamed. But Reason argued that active failures are almost always the final link in a much longer causal chain. The more dangerous weaknesses are LATENT CONDITIONS: organizational decisions and systemic factors that create vulnerabilities long before any individual makes an error. Budget cuts that reduce staffing. Maintenance schedules that are deferred. Training programs that are abbreviated. Regulations that are ambiguous or unenforced.
No single hole in any single layer causes a catastrophe. The holes must align. When a latent weakness in policy coincides with a gap in supervision, which coincides with a degraded precondition, which coincides with an active failure at the operational level, the result is what Reason calls "a trajectory of accident opportunity" — a clear path through all defenses that allows a hazard to become a disaster. As Larouzée and Le Coze noted in their 2020 critical review, the model has become the dominant paradigm for analyzing safety incidents precisely because it shifts attention from blaming individuals to examining the systemic conditions that made their errors possible — and lethal.
[short pause]
The Grenfell Tower fire is a devastating case study in hole alignment. The Phase one Inquiry Report, documented by Moore-Bick in 2019, revealed layer upon layer of degraded defenses. At the policy level: building regulations that permitted combustible cladding materials. At the supervisory level: inadequate training of incident commanders in recognizing the need for a building-wide evacuation and the failure to revise the "stay put" strategy when conditions changed. At the preconditions level: a building lacking a central fire alarm, sprinkler system, or adequate firebreaks in the cladding. At the level of actions: the continued issuance of stay-put advice long after the fire had breached all containment.
No single failure killed seventy-two people. The alignment of failures across every defensive layer did.
Consider an organization you are familiar with. Can you identify latent conditions — policies, staffing decisions, deferred maintenance, inadequate training — that currently represent "holes" in its defensive layers? What would it take for those holes to align?
[short pause]
Reason's model explains how the conditions for crisis accumulate. But it does not fully explain what happens to the people inside a crisis once it has begun. For that, we turn to Karl Weick's sensemaking framework — and to one of the most devastating case studies in organizational theory.
SENSEMAKING, as Weick defined it in 1988, is the ongoing process by which people construct plausible explanations for what is happening around them. It is not simply "understanding" — it is the active, social process of creating a shared narrative that allows coordinated action. In normal operations, sensemaking is so automatic that we scarcely notice it. We walk into a meeting, read the room, infer the agenda, and adjust our behavior accordingly. The cues in our environment are familiar, the roles are clear, and our shared frameworks for interpretation are stable.
Crisis destroys all of this. When the environment suddenly becomes unfamiliar, when the cues contradict our expectations, when the roles that define our identity are stripped away, the process of sensemaking can collapse — and with it, the capacity for coordinated action, as Weick argued in 1993. As Maitlis and Christianson observed in their 2014 comprehensive review of the sensemaking literature, this collapse is especially dangerous because it can happen faster than the physical threat advances. People do not simply face a dangerous situation; they face a situation they can no longer understand, and it is the loss of understanding, not the danger itself, that paralyzes them.
[short pause]
On August fifth, 1949, fifteen smokejumpers parachuted into Mann Gulch, Montana, to fight what appeared to be a routine wildfire. Within two hours, thirteen of them were dead. Weick's 1993 analysis of this disaster — "The Collapse of Sensemaking in Organizations" — remains one of the most cited articles in organizational theory, not because of the fire itself, but because of what it reveals about how groups lose the ability to understand what is happening to them.
The crew that jumped into Mann Gulch was a minimal organization — a group with limited shared experience, thin role structures, and shallow interpersonal trust. When conditions changed rapidly — the fire crossed the gulch and cut off their route to the river — the crew's shared framework for understanding the situation disintegrated. Their foreman, Wagner Dodge, did something unprecedented: he lit an escape fire, burning away the grass around him so the approaching fire would pass over the cleared ground. He shouted to his crew to join him in the ashes.
No one did. Not because they were irrational, but because Dodge's action was incomprehensible within their existing framework. You do not light a fire when you are running from a fire. The act made no sense — and in a situation where sensemaking had already collapsed, an action that could not be interpreted was an action that could not be followed. Dodge survived. Most of his crew did not.
What makes Mann Gulch a compelling case is that people drop their defining roles. The smokejumpers lose their tools, but more fundamentally, they lose their roles — and with their roles they lose the framework that made sense of what was happening to them, as Weick described.
Weick identified four sources of resilience that might have prevented the collapse: improvisation, the ability to invent new responses; virtual role systems, the ability to imagine and coordinate roles mentally; the attitude of wisdom, knowing that you do not fully understand the situation; and respectful interaction, the social fabric that holds collective understanding together. At Mann Gulch, none of these were sufficiently developed. The organization was too thin, too new, and too reliant on a single framework that the fire had already rendered obsolete.
Weick argues that sensemaking is social — it depends on shared frameworks and interpersonal trust. Consider a team you have worked with. How deep was your shared framework for understanding unexpected situations? If something truly unprecedented happened, would the team's sensemaking hold, or would it fragment into individual interpretations?
[short pause]
The distinction between incidents, emergencies, and crises is not an academic exercise. It determines the entire architecture of the leadership response. Consider the differences across just three dimensions:
Tempo. Incident response operates at normal organizational pace. Emergency response accelerates — more resources are mobilized, communication frequency increases, decision authority elevates. Crisis response demands a fundamentally different rhythm: rapid cycling between action and reassessment, because the situation itself is changing in ways that invalidate previous decisions. At Grenfell, the fire brigade continued operating at emergency tempo when crisis tempo was required, as documented in the 2019 inquiry report.
Authority structures. Incidents are handled within normal chains of command. Emergencies typically activate pre-established command structures — a gold-silver-bronze framework, an incident management team, a crisis operations center. Crises often demand the abandonment of normal authority structures because those structures were designed for situations that are already understood. Wagner Dodge's escape fire was an act of improvised authority that fell outside any existing command structure — which is precisely why his crew could not follow it.
Communication. Incident communication is routine and internal. Emergency communication is broader and more frequent but still follows established channels. Crisis communication must be fundamentally different: it must openly acknowledge uncertainty, resist premature narrative closure, and actively seek disconfirming information. As Weick argued in 1988, sensemaking in crisis requires leaders to act in order to discover what is happening — but this means communicating tentative, evolving interpretations rather than confident, fixed ones.
When an organization applies emergency procedures to a crisis, the result is not merely inefficiency — it is the systematic production of the wrong decisions at the worst possible time. The stay-put advice at Grenfell was the correct emergency procedure applied to a crisis situation. The crew at Mann Gulch ran uphill because that was the correct emergency response to a wildfire that had not yet become something else entirely.
Getting the classification right is not the beginning of effective leadership. It is effective leadership, in its most fundamental form.
[short pause]
This chapter has introduced three frameworks that will undergird every subsequent class in this course. Boin and colleagues' crisis characteristics give us a precise vocabulary for classifying adverse events and understanding why crises demand a fundamentally different leadership response. Reason's Swiss Cheese model reveals how crises emerge — not from single dramatic failures, but from the quiet, systemic accumulation of latent conditions that create the preconditions for catastrophe. Weick's sensemaking framework explains what happens to human cognition and collective coordination inside a crisis, and why the capacity to understand what is happening can collapse at precisely the moment it matters most.
Together, these frameworks form a diagnostic toolkit. In the chapters ahead, we will use them to examine how leaders detect crises, how they make decisions under deep uncertainty, how they communicate when they do not fully understand what they are communicating about, and how they rebuild organizational sensemaking after it has collapsed. But all of that depends on this chapter's foundational insight: not every emergency is a crisis, and confusing the two is the first and most consequential leadership failure.
[short pause]
Let's review the key takeaways. Crises are defined by the simultaneous presence of threat, urgency, and deep uncertainty — remove any one, and the leadership challenge changes fundamentally. Incidents, emergencies, and crises require categorically different leadership responses in terms of tempo, authority structures, and communication. Reason's Swiss Cheese model demonstrates that crises emerge from the alignment of multiple systemic weaknesses across organizational defense layers, not from single failures. Latent conditions — budget cuts, deferred maintenance, inadequate training, ambiguous policies — are more dangerous than active failures because they persist unnoticed until holes align. Sensemaking is the active, social process of constructing shared understanding; in crisis, it can collapse faster than the physical threat advances. The Mann Gulch disaster illustrates that when roles and shared frameworks disintegrate, even life-saving innovations, like Dodge's escape fire, cannot be followed because they cannot be understood. Misclassifying a crisis as an emergency — as occurred at Grenfell Tower — leads to the systematic application of the wrong response at the worst possible time.
[short pause]
In the next class, we move from recognizing crises to detecting them before they fully emerge. We will examine the concept of weak signals — the early, ambiguous indicators that a system is drifting toward failure — and explore why organizations systematically ignore, misinterpret, or suppress the very information that could prevent catastrophe. Using the frameworks established in this chapter, we will analyze cases where crises were foreseeable but unforeseen, and begin developing the leadership capacity to see what others miss.













The First Thirty Minutes
The opening phase of a crisis is where the most consequential decisions are made with the least available information. This chapter examines the critical period of activation and initial mobilisation — the gap between…
Have you ever convinced yourself something wasn't 'bad enough' to deal with yet... and then regretted waiting?
Real talk
Would you rather overreact to 10 false alarms or miss 1 actual emergency?
Would you rather
When chaos breaks out and nobody's clearly in charge, are you the person who steps up or the person who waits to see who steps up?
Quick poll
You think something's seriously wrong but everyone around you seems fine. Do you trust your gut or trust the crowd?
Debate time
When everything's happening at once: try to get ALL the facts first, or just make a call with what you've got?
Hot take
Which is worse — a leader who acts too fast or one who waits too long?
Pick your poison
Crisis Timeline: When Do We Escalate?
15-20 minutesInstructor releases information about a developing crisis in 5 waves (every 2-3 minutes). After each wave, teams have 90 seconds to decide: (1) Do we escalate NOW? (2) To whom? (3) What's our activation threshold? Teams record their decisions on worksheets. After all waves, instructor reveals what actually happened and teams compare their escalation decisions—debate ensues about who escalated too early, too late, or to the wrong people. Debrief focuses on how different tables interpreted the same information differently and what triggered their activation thresholds.
Who's In Charge Here? Role Negotiation Under Pressure
12-15 minutesTeams receive a crisis scenario with a deliberately vague organizational chart showing overlapping responsibilities. They have 8 minutes to assign roles and create an action plan. Twist: The instructor interrupts at the 4-minute mark with 'breaking news' that changes the situation—forcing teams to renegotiate roles on the fly. Teams then pair with an adjacent table to compare their org structures and defend their choices. Instructor facilitates whole-room discussion on why the same scenario produced wildly different command structures.
Signal vs. Noise: Information Triage Challenge
10-12 minutesEach team receives an envelope with 25 information cards about a developing situation—mix of critical signals, irrelevant noise, rumors, and red herrings. Teams have 5 minutes to sort information into three piles: ACT NOW, MONITOR, and IGNORE. Instructor calls time and reveals which 5 pieces were actually critical. Teams calculate their 'triage score' (points for catching critical info, penalties for missing it or acting on noise). Top 3 teams explain their sorting criteria. Debrief focuses on what heuristics worked and what led teams astray.
The Bureaucracy Gauntlet: Escalation Obstacle Course
15-18 minutesTeams identify a potential crisis in their assigned scenario and must escalate it. But the instructor plays 'the system'—enforcing realistic institutional barriers: 'Submit that request in writing,' 'Your manager is in a meeting,' 'We need three levels of approval,' 'Are you sure this is an emergency?' Teams must navigate these obstacles while the clock ticks. After 10 minutes, freeze the action and map out: which teams successfully escalated, which got stuck, and where. Discuss how institutional inertia kills crisis recognition and what tactics worked to break through.
The Incident Commander Hot Seat
12-15 minutesEach team designates one member as 'Incident Commander' for a 3-minute round. Teammates act as different information sources (911 dispatch, social media monitor, facility manager, etc.) and simultaneously feed the IC conflicting, incomplete information. The IC must make rapid decisions: What do you need to know? Who do you notify? What's your first action? After 3 minutes, rotate to a new IC with a different scenario. Debrief compares how different ICs handled information overload and what decision-making patterns emerged under pressure.
Case Study Speed Dating: Learning from Failure
15-18 minutesEach team receives a different real-world crisis case (Columbia shuttle, Deepwater Horizon, COVID-19 initial response, etc.) focused on the first 30 minutes. Teams have 7 minutes to identify: (1) When should recognition have happened? (2) What barriers prevented it? (3) What would you have done differently? Then, teams rotate representatives in 2-minute 'speed teaching' rounds—one person stays to present their case while others visit neighboring tables to learn about different crises. After 3 rotations, reconvene to identify patterns: What common failure modes appear across all cases?
Transcript
At three twenty-seven p.m. on March eleventh, 2011, the largest earthquake in Japan's recorded history had just triggered a massive tsunami racing toward the Fukushima Daiichi Nuclear Power Station. Inside the control rooms, operators watched as external power was lost. Emergency diesel generators kicked in — the system was performing as designed. Fourteen minutes later, a wall of water fourteen meters high overwhelmed the plant's seawall. The generators drowned. Batteries began to fail. In the critical minutes that followed, operators faced a cascade of contradictory instrument readings, severed communication lines, and a situation for which no procedure manual had been written. The question confronting the shift supervisors and plant management was not whether something was wrong — it was staggeringly, obviously wrong — but rather: how wrong is this, and what mode of response does it demand?
[short pause]
Seven thousand kilometers away and seven years later, a group of boys from a Thai football team and their coach wandered into the Tham Luang cave complex after practice. When monsoon rains flooded the entrance, the local governor activated emergency protocols within hours, and an international rescue coordination effort was underway before most of the world even knew the boys were missing. The contrast between these two cases — one defined by catastrophic delay, the other by remarkably swift mobilization — illuminates something fundamental about crisis leadership: the first thirty minutes don't just shape the response. They ARE the response.
[short pause]
Every crisis has an inflection point — a moment when the situation crosses from manageable abnormality into something that demands a fundamentally different mode of operating. The distance between recognizing that threshold and actually crossing it in organizational terms is what we might call the ACTIVATION GAP: the period between "something is wrong" and "we are now in crisis response mode." Research consistently shows that this gap is where the most consequential decisions are made, almost always with the least available information, as Boin and colleagues found in 2016.
The activation gap is not primarily a problem of speed, though speed matters. It is a problem of recognition. Barry Turner's foundational work on man-made disasters identified what he called the INCUBATION PERIOD — a phase in which warning signals accumulate but are systematically overlooked, misinterpreted, or rationalized away. As Turner and Pidgeon described in 1997, Turner identified four categories of information failure that characterize this period: information that is completely unknown; information that exists but is not fully appreciated; information that exists but is not correctly assembled; and information that does not fit existing mental models. All four of these failures are dramatically compressed during the first thirty minutes of an acute crisis, when the incubation period collapses and the event itself arrives.
What makes this opening phase so treacherous is not the absence of information — there is usually quite a lot of it — but rather the abysmal signal-to-noise ratio. Reports flood in from multiple sources, many of them contradictory, incomplete, or distorted by the stress and confusion of the moment. Leaders must make sense of this stream while simultaneously deciding whether to activate emergency protocols that, once triggered, carry significant organizational and sometimes political costs. This dual burden — sensemaking and deciding simultaneously — is what Weick identified in 1988 as the central paradox of crisis: the actions you take to understand the situation often change the situation itself.
[short pause]
An activation threshold is the point at which an organization shifts from routine operations to crisis response mode. It sounds simple in theory — you set criteria, and when those criteria are met, you activate. In practice, activation thresholds are among the most poorly designed elements of organizational preparedness. The Institute of Medicine's toolkit on crisis standards, published in 2013, distinguishes between indicators — data points that suggest a situation is developing — and triggers — specific thresholds that demand action — noting that the gap between the two is where most organizations struggle. An indicator might be a sensor reading that is slightly above normal; a trigger is the determination that the reading represents a genuine emergency requiring immediate resource mobilization.
The challenge is that activation carries costs. Declaring a crisis when one does not materialize — a false positive — wastes resources, disrupts operations, erodes credibility, and can create a "cry wolf" dynamic that makes future activation harder. As Boin and colleagues documented in 2020, this calculation produces a systematic bias toward under-activation. Organizations develop what might be called an institutional immune response that resists the disruption of emergency mobilization. The more bureaucratic the organization, the stronger this resistance tends to be.
[short pause]
The Fukushima Daiichi disaster illustrates this failure with devastating clarity. After the tsunami struck and backup power was lost, plant operators and management faced a cascading series of escalation decisions. The National Research Council's subsequent investigation in 2014 revealed that decision-making was paralyzed by the lack of reliable, real-time information on plant status. Instrument readings were unreliable or absent. Communication between the control room, plant management, and TEPCO's — the Tokyo Electric Power Company's — Tokyo headquarters was fragmentary. At each escalation point — from declaring an emergency at the plant level, to requesting external assistance, to ordering civilian evacuation — there was delay. Not because individuals were incompetent, but because the system was designed to process information through layers of confirmation and approval that were wholly inadequate for the speed of the unfolding event.
The report documented how emergency management plans were "inadequate to deal with the magnitude of the accident, requiring emergency responders to improvise." This is a critical insight: when formal activation protocols fail, the quality of the response depends entirely on the ability of individuals to improvise — and improvisation without clear role authority creates its own cascading failures.
[short pause]
The Tham Luang cave rescue presents a striking counter-example. When the boys failed to return from practice, the alarm was raised quickly. Chiang Rai's provincial governor, Narongsak Osatanakorn, assumed incident command and activated emergency coordination protocols that rapidly scaled from local to national to international scope. The Australian Government's post-rescue analysis in 2018 identified several factors that enabled this swift activation: pre-existing relationships between Thai emergency agencies, a cultural willingness to escalate without excessive procedural gatekeeping, and crucially, a single decision-maker with clear authority to activate and expand the response.
What distinguished Tham Luang was not that the situation was simpler — a flooded cave system with thirteen lives at stake and no proven rescue methodology was extraordinarily complex — but that the activation architecture was clear. The governor did not need to convene a committee to decide whether this constituted a crisis. The threshold was unambiguous, the authority to activate was vested in a single role, and the escalation pathway from local to national to international resources was well-defined.
[short pause]
If timely activation saves lives and resources, why do organizations so often fail at it? Boin and colleagues in 2016 identify several interacting barriers that operate at the institutional level, distinct from the cognitive biases explored earlier. First, there is the problem of distributed information: the person who first detects an anomaly is rarely the person with the authority to activate a crisis response. Information must travel upward through organizational layers, and at each layer it is subject to filtering, reinterpretation, and delay. Second, organizations develop NORMALCY ROUTINES — deeply embedded patterns of behavior that assume events fall within normal operating parameters. These routines are efficient under ordinary conditions but become actively dangerous when conditions are extraordinary.
Boin and colleagues' later work on "creeping crises" extends this analysis, documenting how threats that develop gradually can pass entirely through organizational detection filters. The psychological factors are formidable: the inconceivability of certain events, communication failures across organizational boundaries, and the challenge of recognizing threats that do not conform to existing mental models. These are not failures of intelligence or diligence; they are structural features of how organizations process information.
Maitlis and Christianson in 2010 build on Weick's framework to argue that crisis and change contexts are "especially likely to impede sensemaking processes" because they disrupt the shared meanings and emotional equilibrium that sensemaking depends upon. When the emotional temperature in an organization spikes — when people are frightened, confused, or overwhelmed — the very cognitive processes needed to interpret the situation are degraded. This creates a vicious cycle: the more severe the crisis, the harder it is to recognize it as such, because the cognitive resources needed for recognition are consumed by the emotional demands of the situation.
As Boin and colleagues wrote in their 2016 book The Politics of Crisis Management: "Organizations are not designed to look for crises. They are designed for efficiency, for routine, for the smooth processing of predictable inputs. The detection of crisis requires precisely the opposite orientation — a vigilance toward the anomalous, the unexpected, the signals that do not fit."
[short pause]
Even when the activation threshold is crossed, a second challenge immediately emerges: role clarity. Who is in charge? Who does what? In routine operations, role assignments are well-understood and largely automatic. In the opening minutes of a crisis, formal organizational structures are often suddenly insufficient. The normal chain of command may be disrupted — key personnel may be unreachable, the nature of the crisis may fall outside any single department's jurisdiction, or the scale of the event may overwhelm the resources assigned to normal emergency roles.
The Tham Luang rescue symposium report emphasized that one of the most critical success factors was the early establishment of clear command, control, and coordination structures that spanned strategic, operational, and tactical levels. This was not accidental. Thai disaster management frameworks vest clear authority in provincial governors for events within their jurisdiction, which meant that the question "who is in charge?" had an immediate, unambiguous answer.
Contrast this with Fukushima, where command authority was fragmented between the plant operator TEPCO, the nuclear regulator, the Prime Minister's office, and local government officials responsible for evacuation. The National Research Council report documented how this fragmentation produced conflicting directives, duplicated efforts, and critical gaps where no one believed they held responsibility.
[short pause]
Role clarity is not just about knowing who is in charge — it is about understanding the mobilization sequence: the order in which roles are activated and the dependencies between them. A common failure mode is activating resources before the situation assessment that determines what resources are needed. Another is failing to activate communications capacity early enough, which means that subsequent mobilization decisions cannot be effectively transmitted. The sequence matters because crisis response is not a parallel process where everything happens simultaneously — it is a cascading series of dependent actions where early decisions constrain later options.
[short pause]
Once activation has occurred and roles are being mobilized, the next critical challenge is information triage — the process of sorting, prioritizing, and routing the flood of incoming data. In the opening phase of a crisis, information arrives from multiple sources simultaneously: automated sensor systems, eyewitness reports, social media posts, media inquiries, peer agency notifications, and internal status updates. Much of this information is incomplete, contradictory, or simply wrong. The leader's task is not to process all of it — that is impossible — but to identify the signals that matter most and route them to the people who can act on them.
Weick's concept of ENACTED SENSEMAKING is particularly relevant here. As Weick argued in 1988, sensemaking in crisis is not a passive process of receiving and interpreting information — it is an active process in which the actions you take to understand the situation shape what information becomes available and relevant. When a leader decides to focus attention on one data stream, they necessarily de-prioritize others. When they commit resources to investigating one hypothesis, they constrain their capacity to investigate alternatives. "Action precedes cognition and focuses it," Weick wrote, "emphasizing that specific action renders many cues irrelevant and consolidates an otherwise unorganized set of environmental elements."
This creates a fundamental tension in information triage. Acting on early information is necessary to shape the response, but acting too quickly on unreliable information can commit the organization to a course of action that becomes difficult to reverse. As Maitlis and Christianson described in 2010, this is the challenge of maintaining "sensemaking fluidity" — the capacity to hold multiple interpretations simultaneously and revise them as new information arrives, rather than prematurely locking onto a single narrative.
[short pause]
Effective information triage depends on establishing what we might call an information hierarchy: a structured understanding of who needs to know what, and in what order. During the first thirty minutes, not everyone needs all the information. The incident commander needs situation awareness — a broad picture of what is happening and what resources are available. Operational leads need specific, actionable intelligence relevant to their function. External communications personnel need verified facts they can release without creating additional confusion. Political and senior leadership need enough context to make strategic decisions without being overwhelmed by operational detail.
Turner and Pidgeon's framework in 1997 suggests that the most dangerous information failures are not missing data but misassembled data — information that exists within the system but is not correctly combined to reveal the true picture. In the first thirty minutes, this assembly function is perhaps the most critical and most difficult leadership task. It requires someone — usually the incident commander or a dedicated intelligence function — to hold the threads together and continually ask: "What picture does this information paint, and what are the most important things we still don't know?"
[short pause]
The first thirty minutes of a crisis set a trajectory that is extraordinarily difficult to alter. Early activation decisions determine which resources are available and which are not. Early role assignments create command structures that persist even when they prove suboptimal. Early information triage decisions establish narratives that shape subsequent interpretation. As Weick described in 1988, this is the commitment dimension of sensemaking: once an organization commits to a particular interpretation and course of action, the psychological and structural investments in that commitment make reversal costly and unlikely.
This does not mean that early decisions must be perfect — perfection is impossible with fragmentary information. It means that early decisions must be designed for revision. The most effective crisis leaders make initial decisions that preserve optionality: activating broadly rather than narrowly, establishing communication channels before they are needed, and explicitly flagging assumptions that need to be tested as more information arrives. They treat the first thirty minutes not as the period in which the right answer must be found, but as the period in which the capacity to find the right answer must be built.
[short pause]
The contrast between Fukushima and Tham Luang is ultimately a story about trajectory. At Fukushima, delayed activation, fragmented authority, and overwhelmed information systems set a trajectory toward cascading failure that brave individual actions could slow but not reverse. At Tham Luang, swift activation, clear authority, and effective coordination set a trajectory toward successful resolution despite enormous technical challenges. The boys were trapped for eighteen days — but the response architecture that would eventually save them was established in the first hours.
As Boin and colleagues remind us in 2016, crisis management is fundamentally a political activity, not merely a technical one. The decisions made in the first thirty minutes are shaped by institutional cultures, power structures, legal frameworks, and the individual courage of the people who happen to be on duty when the call comes in. Understanding these dynamics — and designing systems that account for them — is the difference between organizations that survive crises and organizations that are consumed by them.
[short pause]
To summarize the key insights: The activation gap — the distance between recognizing something is wrong and entering crisis response mode — is where the most consequential decisions are made with the least information. Activation thresholds must distinguish between indicators, which are data points suggesting a problem, and triggers, which are specific thresholds demanding action. Organizations systematically bias toward under-activation due to the costs of false positives. Turner's four categories of information failure — unknown, unappreciated, unassembled, and unfitting information — are dramatically compressed during the first thirty minutes of an acute crisis.
Role clarity is not just about who is in charge, but about the mobilization sequence: the order of activation and the dependencies between roles that determine whether resources arrive in a usable configuration. Information triage requires balancing the need to act on early data against the risk of committing to interpretations based on unreliable information — this is Weick's insight that action precedes and focuses cognition.
The institutional barriers to crisis recognition — normalcy routines, distributed information, and organizational resistance to disruption — are structural features, not individual failures, and must be addressed through system design. Early decisions should be designed for revision: preserving optionality, establishing communication capacity, and explicitly flagging assumptions that need testing as information improves. The first thirty minutes set a trajectory that becomes exponentially harder to alter — as demonstrated by the contrasting outcomes at Fukushima Daiichi and Tham Luang.
[short pause]
Looking ahead: In the next chapter, we move from the opening phase into the sustained crisis environment and examine decision-making under deep uncertainty — what happens when the initial mobilization is complete but the situation continues to evolve in unpredictable ways. We will explore how leaders make high-stakes choices when they cannot wait for complete information, including the use of decision frameworks, the role of intuition versus analysis, and the dangers of both paralysis and premature commitment. The information hierarchy concept introduced here will become a central focus in later discussions, where we examine how communication architectures determine what leaders know, when they know it, and what they can do with it.











Thinking in the Burning Building
When the building is on fire — literally or figuratively — you do not have time to convene a working group. This chapter tackles the central cognitive challenge of crisis leadership: how do experienced professionals…
You're taking a final exam and totally blank on a question. Do you go with your gut instinct or spend 10 minutes reasoning it out? Which strategy has actually worked better for you?
Gut or logic?
Have you ever made a terrible decision because you were stressed or rushed? What would you have done differently with more time to think?
Pressure fail
Is it better to make a decent decision RIGHT NOW or a perfect decision 5 minutes from now? When does speed matter more than being right?
Fast vs. perfect
You see someone collapse on the sidewalk. Do you immediately help, freeze up, or stop to think through what to do? Be honest — what actually happens in your brain?
Crisis mode
When was the last time overthinking ruined something for you? Like you analyzed it so much you made it worse than if you'd just acted?
Analysis paralysis
Do you trust people who make snap decisions, or do they seem reckless? What about people who need to carefully think through everything — wise or indecisive?
Quick poll
The Rapid-Fire Scenario Gauntlet
15-20 minutesEach table receives a series of 5 emergency scenarios (medical crisis, building evacuation, product recall, etc.). Round 1: Teams have 3 minutes per scenario to analyze and decide. Round 2: Same complexity scenarios, but only 30 seconds each. Teams record their decisions and confidence levels. Afterward, compare how decision quality and process changed under time pressure. Debrief: Which decisions felt more 'right' despite less analysis time? When did pattern recognition kick in?
Expert Pattern Recognition Challenge
12-15 minutesShow 10 images for 3 seconds each (chess positions, medical scans, fire scenes, etc.). Novice round: Students at each table try to identify what they see and what to do. Expert round: Provide them with 2 minutes of 'expert training' (pattern primers like 'look for X configuration'). Show same images again. Tables discuss: How did the primer change their recognition speed? This simulates Klein's finding that experts 'see' patterns novices miss. Debrief focuses on how experience builds recognition-primed intuition.
Cognitive Load Collapse
10-12 minutesThree-stage challenge at each table. Stage 1 (baseline): Simple decision task (ranking 5 options). Stage 2 (moderate load): Same task while one person reads random numbers they must remember. Stage 3 (high load): Same task while doing mental math, remembering numbers, AND someone asking unrelated questions. Track decision time and quality. Students physically experience decision degradation. Debrief: At what point did you start satisficing? When did you just want it over?
The Satisficing Defense Trial
15-18 minutesAssign half the tables 'Prosecution' (satisficing is dangerous corner-cutting) and half 'Defense' (satisficing is adaptive expertise). Present a real case (e.g., firefighter who made quick call that saved lives but violated protocol). Teams prepare 3-minute arguments, then tables pair up prosecution-vs-defense for mini-debates. Rotate partners twice. Debrief: When is satisficing wise? When is it reckless? How do you tell the difference in the moment?
Decision Autopsy Gallery
12-15 minutesPost 6 real-world decision cases around the room (Sully's Hudson landing, ER triage call, startup pivot, etc.). Each table visits 2-3 cases (4 minutes each). Using RPD model framework, they annotate poster paper: What cues did the decider recognize? What patterns matched? What was the mental simulation? Tables leave sticky notes with insights. Final 3 minutes: Quick gallery walk to see all annotations. Discuss which decisions were truly RPD vs. forced analytical.
System 1 vs System 2 Showdown
15-18 minutesPresent a complex scenario (hospital resource allocation during crisis). Half of each table uses ONLY gut instinct/first response (2 minutes max, System 1). Other half uses structured analytical method (pros/cons grid, 8 minutes, System 2). Teams compare their answers, quality, and confidence. Switch methods and try a second scenario. Debrief: When did each system produce better results? When did they converge? When did speed matter more than perfection?
Transcript
It is January 15, 2009, and Captain Chesley "Sully" Sullenberger has just lost both engines on US Airways Flight 1549 at an altitude of 2,818 feet over one of the most densely populated places on Earth. He has 155 souls aboard and roughly 208 seconds before the aircraft hits something. Air traffic control offers him two runways — Teterboro to the west, LaGuardia behind him. The rational thing to do, according to classical decision theory, would be to evaluate each option against weighted criteria: distance, glide ratio, wind conditions, obstacle clearance, passenger survival probability. Sullenberger does none of this. Within seconds, he makes a decision that no simulator had ever trained him for. "We're gonna be in the Hudson," he tells the controller. His voice is flat, certain. It is not the voice of a man running probability calculations. It is the voice of a man who has seen the answer.
[short pause]
How did he see it? And what, precisely, was happening inside his mind that made that seeing possible — or that might, under slightly different conditions, have made it catastrophically wrong?
[short pause]
For most of the twentieth century, the dominant model of good decision-making was the rational choice model: identify the problem, generate a comprehensive set of options, evaluate each option against defined criteria, select the optimal one. This model, rooted in economic theory and refined in operations research, works beautifully in boardrooms, planning committees, and academic examinations. It is how we teach Master of Business Administration students to think. It is how we structure strategic plans. And it is almost entirely useless when the building is on fire.
Herbert Simon saw the problem decades before anyone studied fire commanders. In his book Administrative Behavior, as Simon described in 1947, he introduced the concept of BOUNDED RATIONALITY — the recognition that human decision-makers cannot evaluate all alternatives because they lack the time, the information, and the cognitive capacity. Instead, they satisfice: they set an aspiration level for what constitutes an acceptable outcome and choose the first option that meets it. Good enough, fast enough. This was heresy in an era that worshipped optimization, but Simon won a Nobel Prize for it, because he was describing how humans actually behave rather than how economists wished they would.
Yet even Simon's model implies a degree of deliberation — setting criteria, scanning options, evaluating whether each meets the threshold. What happens when you have neither the time to scan nor the cognitive bandwidth to evaluate? What happens when the decision must be made in seconds, the information is ambiguous or contradictory, and the consequences of getting it wrong are measured in human lives?
That question drove a young cognitive psychologist named Gary Klein into fire stations, military command posts, and neonatal intensive care units in the early 1980s. What he found there overturned nearly everything the decision sciences thought they knew.
[short pause]
Klein's original study was elegantly simple in design and revolutionary in findings. He and his colleagues interviewed 26 experienced fireground commanders — professionals with an average of 23 years of service — about 156 critical decisions made during actual fires, as Klein and colleagues reported in 2010. The research question was straightforward: when you face a life-or-death decision under extreme time pressure, how do you choose what to do?
Classical decision theory predicted that commanders would generate several courses of action and compare them. They did not. In 80 to 90 percent of the decisions Klein studied, commanders reported considering only a single option. They did not compare. They recognised, as Klein described in 1998.
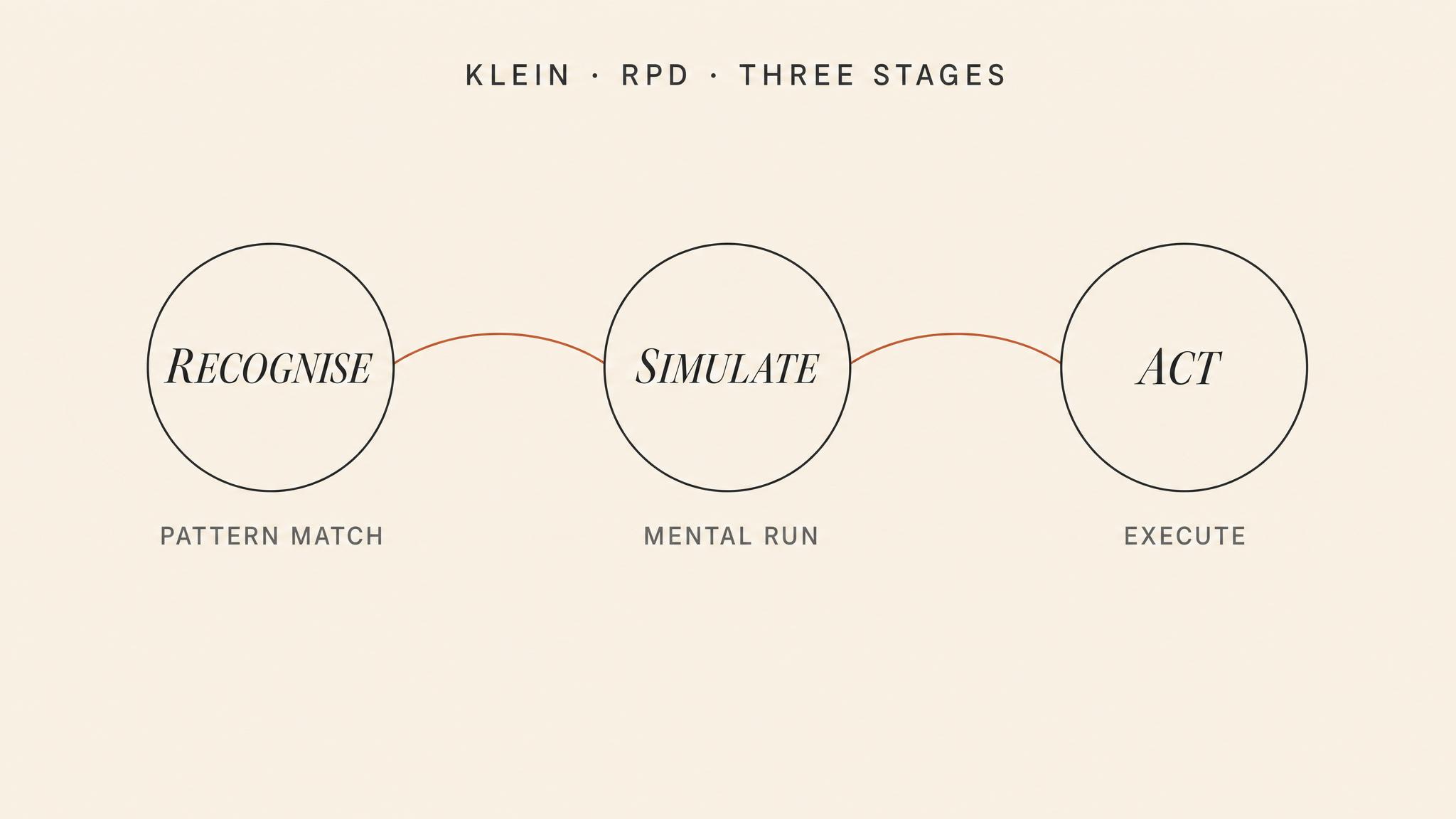
The model Klein developed from these findings — the RECOGNITION-PRIMED DECISION model, or RPD model — describes a three-stage process that experienced professionals use under pressure:
First, situation recognition. The decision-maker rapidly categorizes the current situation by matching it against patterns stored from prior experience. A fireground commander arriving on scene does not see a building on fire — she sees this kind of fire: a ventilation-controlled basement fire in a balloon-frame structure, or a wind-driven high-rise fire with extension to the floor above. Each pattern carries with it a set of expectancies, relevant cues, plausible goals, and typical actions.
Second, mental simulation. Having recognized the pattern, the decision-maker mentally simulates a single course of action: if I do this, will it work? She runs the scenario forward in her mind, looking for problems. If the action holds up under mental simulation, she executes it. If it breaks — if she imagines a point of failure — she modifies the action or, less commonly, recognizes a different pattern and simulates again.
Third, action. The decision-maker commits. The entire process, from recognition to action, can take seconds.
[short pause]
This is not guessing. It is not recklessness. It is what Klein, in 2008, called NATURALISTIC DECISION MAKING — the study of how experienced people make decisions in real-world settings characterized by time pressure, high stakes, ambiguous information, and dynamic conditions. The naturalistic decision making framework emerged precisely because laboratory studies of decision-making — which typically gave subjects unlimited time, clear options, and defined probabilities — were describing a world that crisis leaders never inhabit.
The critical insight of RPD is that expert intuition is not mystical. It is compressed experience. A fireground commander with 23 years of service has seen thousands of fires. Those experiences are stored not as explicit rules but as patterns — perceptual configurations that bundle together cues, expectations, and actions. When a new situation arrives, the commander's brain does what brains do extraordinarily well: it matches the incoming information to a stored pattern, often before the commander can articulate why. Klein calls this "seeing the invisible" — experienced professionals literally perceive features of a situation that novices cannot, because their perceptual systems have been trained by years of pattern exposure.
[short pause]
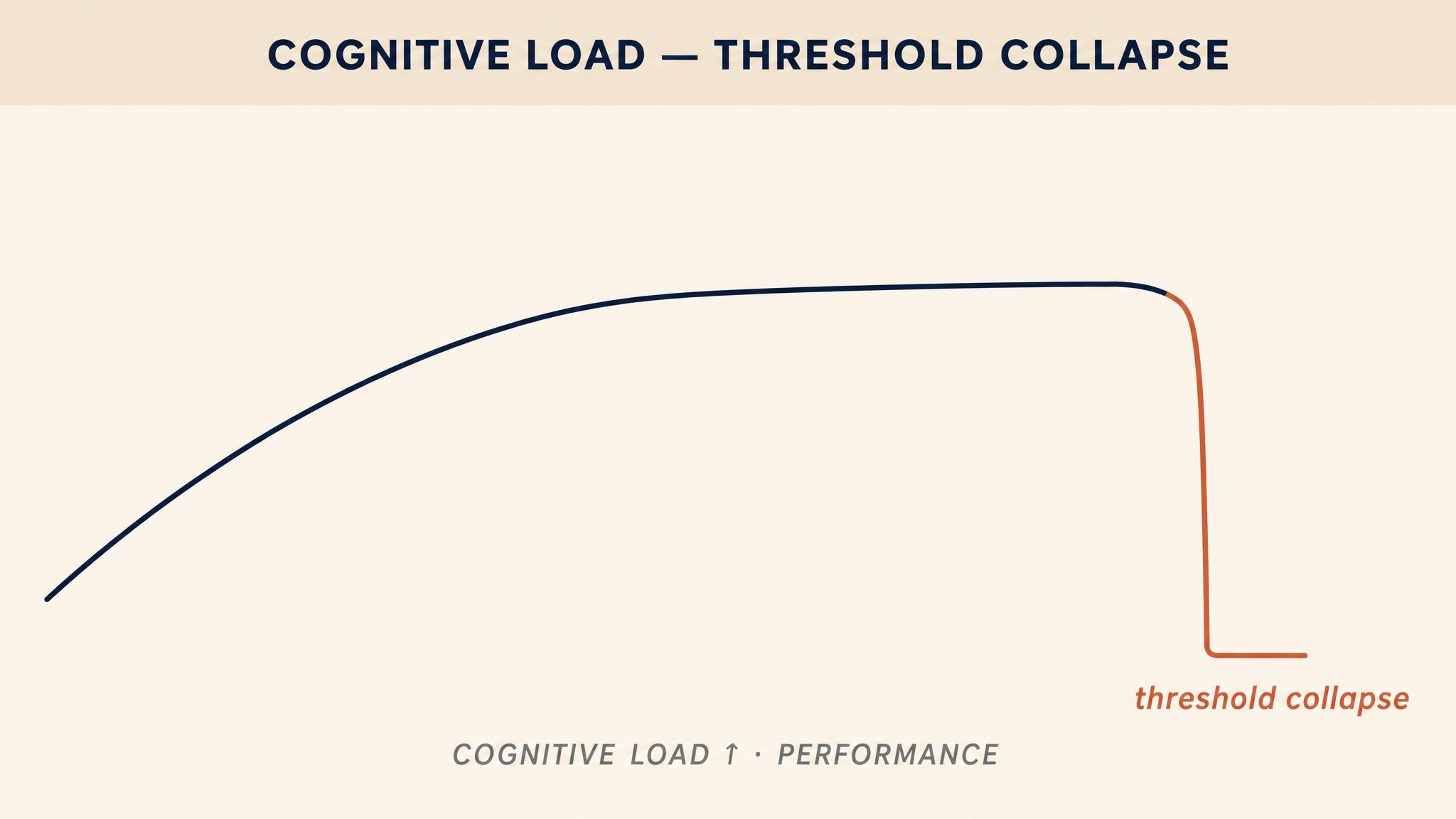
Recognition-primed decision making is powerful, but it is not invulnerable. It requires cognitive resources — specifically, it requires that the decision-maker's working memory be available for pattern matching and mental simulation. When that working memory is overwhelmed, the entire system degrades. And it does not degrade gently.
Research on COGNITIVE LOAD consistently demonstrates that decision quality does not decline in a smooth, linear fashion as demands increase. Instead, performance holds relatively steady across a range of increasing load, and then drops sharply — a threshold collapse. Research by Allen and colleagues in 2014 found that when participants were placed under cognitive load by memorizing an eight-digit number while making decisions, their ability to extract basic information remained intact, but their capacity to optimize choices — to think strategically — was severely suppressed. The implication is stark: under high cognitive load, you can still read the gauges, but you can no longer figure out what they mean together.
Findings by Deck and Jahedi in 2015 extended these results, showing that cognitive load increases risk aversion, reduces numerical reasoning, and makes decision-makers more susceptible to anchoring — fixating on the first piece of information they encounter, even when it is irrelevant. Under load, the analytical system that might catch errors or question initial impressions is effectively taken offline, leaving the faster, more automatic system to operate without supervision.
For crisis leaders, this threshold effect has two critical implications. First, you must manage your own cognitive load. Every additional demand — a ringing phone, a side conversation, an unresolved question held in working memory — pushes you closer to the threshold. Second, and perhaps more importantly, you must manage the cognitive load of your team. A leader who piles simultaneous demands on a subordinate during a crisis is not merely being inconsiderate; she is systematically degrading the quality of decisions across her entire operation.
[short pause]
How do you recognize cognitive overload in yourself or others? The research identifies several warning signs that experienced leaders learn to watch for:
Tunnel vision: Fixation on a single information source or a single hypothesis, with failure to check alternatives or scan the broader environment.
Shed tasks without noticing: Quietly dropping responsibilities or monitoring duties that feel less urgent — not by deliberate triage, but by unconscious neglect.
Regression to familiar actions: Executing well-practiced routines even when the situation has changed and those routines are no longer appropriate.
Communication breakdown: Increasingly terse or absent communication — the overloaded person literally does not have the bandwidth to talk and think simultaneously.
And emotional flattening or irritability: Either a noticeable loss of affect with robotic responses, or a sharp increase in frustration, both of which signal that executive cognitive resources are depleted.
[short pause]
Let's examine three decisions that illuminate this model. Return to the cockpit of Flight 1549. The National Transportation Safety Board's investigation in 2010 revealed something remarkable about Sullenberger's decision-making. In post-accident simulations, pilots who attempted an immediate return to LaGuardia — without any delay for assessment or decision-making — were able to land safely. But when the simulations added a realistic 35-second delay for the pilots to assess the situation and decide on a course of action, every single attempt to return to the airport failed. The plane crashed into buildings.
Sullenberger's decision to ditch in the Hudson was, in Klein's framework, a textbook recognition-primed decision. He did not compare LaGuardia versus Teterboro versus the Hudson using weighted criteria. He recognized the situation — dual engine failure at low altitude over an urban area — and mentally simulated the return to LaGuardia. In his mind, the simulation broke. He could see they would not make it. The Hudson appeared not as an optimized choice but as the only course of action that survived mental simulation. Critically, he also made several expert decisions that overrode standard procedure: he activated the auxiliary power unit immediately, ahead of checklist sequence, and selected flaps 2 instead of the standard flaps 3, a choice that reduced drag and extended glide distance. These were not analytical calculations. They were the products of decades of accumulated flight experience expressed as pattern recognition.
[short pause]
In Chapter 1, we examined the Mann Gulch disaster as a case of organizational collapse. Now we return to it through a different lens: the decision-making of foreman Wag Dodge in the final minutes before the fire overtook his crew.
As historian Norman Maclean reconstructed in 1992, Dodge realized that the fire had jumped the gulch and was racing uphill toward his crew at a speed that made escape to the ridge impossible. He had perhaps ninety seconds. What Dodge did next was, in Klein's analysis, one of the purest examples of creative decision-making under lethal time pressure ever documented. He stopped running, bent down, and lit a match. He set fire to the grass in front of him, creating a small burned-out area. Then he lay down in the ashes of his own fire and let the main fire burn over him.
No one had ever done this before. There was no training for it, no protocol, no prior pattern to recognize. Dodge invented the ESCAPE FIRE in the moment. Klein has analyzed this decision as a case where RPD's normal pattern-matching mechanism was unavailable — the situation was genuinely novel — and the decision-maker's deep understanding of the domain — how fire behaves, what it needs, what it leaves behind — enabled a creative leap. Dodge's crew, lacking this depth of understanding, saw only a madman lighting a fire in the path of a fire. They ran past him. Thirteen of them died.
Dodge's escape fire was creative genius. But his crew's refusal to follow him was not stupidity — it was also a form of pattern recognition. They had a pattern for what you do when fire chases you: you run. The challenge for leaders is this: How should a leader communicate a genuinely novel course of action when their team's experience patterns are actively working against comprehension? What could Dodge have done differently in those ninety seconds?
[short pause]
The Fukushima Daiichi nuclear disaster of March 2011 offers a contrasting lesson. When the earthquake and tsunami struck, operators at the plant faced an unprecedented situation: the complete loss of electrical power, instrumentation, and cooling systems across multiple reactor units simultaneously. Emergency management plans had never contemplated this scenario, as the National Research Council Committee reported in 2014.
In the critical early hours, decision-makers at Fukushima attempted to use analytical processes — verifying plant status, consulting procedures, seeking authorization through the chain of command — under conditions that demanded faster, more adaptive action. With no reliable instrument readings, operators could not confirm reactor status, which meant they could not match the situation to their trained procedures, which meant they could not act. The procedural framework that was designed to ensure careful decision-making became a paralysis mechanism. Hours were lost in attempts to gather information that simply was not available, while conditions inside the reactors deteriorated beyond recovery.
The lesson is not that analytical thinking is bad. It is that analytical thinking deployed in conditions that require recognition-based or creative action is a form of MODE MISMATCH — and mode mismatch kills.
[short pause]
The central practical question of this chapter is not "which decision mode is best?" It is "which decision mode is appropriate right now?" The answer depends on a dynamic assessment of four factors:
Time available. When time is measured in seconds, recognition-primed decisions are not merely preferred — they are the only option. As available time increases to minutes and hours, analytical approaches become feasible and sometimes necessary.
Novelty of the situation. RPD works when the situation matches a known pattern. When the crisis is genuinely unprecedented — a novel virus, a never-before-seen system failure, a conflict with no historical parallel — pattern matching may lock the decision-maker onto the wrong template. These situations demand creative thinking, which requires a deliberate pause, even when every instinct screams to act.
Expertise of the decision-maker. RPD requires a large library of stored patterns, built through years of relevant experience. A novice cannot recognize patterns that have never been encoded. Novices in crisis situations are generally better served by structured analytical tools — checklists, protocols, decision trees — precisely because they lack the experiential base for reliable intuition.
Stakes and reversibility. When a wrong decision can be corrected, fast recognition-based action with subsequent adjustment is efficient. When a wrong decision is catastrophic and irreversible — launching a military strike, administering a lethal drug dose — the higher cost of error may justify slower analytical verification, even under time pressure.
[short pause]
The most dangerous moments in crisis leadership occur at the boundaries between these modes — when a situation looks familiar but is actually novel, leading to confident pattern matching onto the wrong template, or when novelty is present but time pressure triggers an automatic reversion to known patterns. Expert leaders develop what we might call mode awareness: the metacognitive ability to monitor not just the crisis but their own cognitive process, asking "Am I in the right mode for this situation?"
[short pause]
Simon's concept of SATISFICING gains new urgency in crisis conditions. In a crisis, the search for the optimal decision is not merely impractical — it is actively dangerous, because the time consumed searching for "best" allows the situation to deteriorate past the point where any good option remains. The satisficing leader sets a clear threshold: this action will be adequate to prevent the worst outcome and preserve options for future adjustment. Then she acts.
This requires a psychological discipline that many high-achievers find deeply uncomfortable. Leaders who have been rewarded throughout their careers for finding the best answer, the elegant solution, the thoroughly analyzed recommendation, must learn to override that training in crisis. The perfect is genuinely the enemy of the good when the building is burning. A good-enough decision made now is almost always superior to an optimal decision made too late.
But satisficing has a cost. It requires cognitive resources to set appropriate aspiration levels, to monitor whether the "good enough" decision is actually performing adequately, and to adjust when it is not. In prolonged crises — those lasting days, weeks, or months — the cognitive resources that make satisficing possible are themselves eroded by fatigue, stress, and the cumulative weight of decision after decision. When those resources are finally exhausted, decision-makers do not satisfice; they default. They fall back on the most automatic, most habitual response available, regardless of whether it fits the situation. This dynamic — the erosion of satisficing capacity over time — is a critical vulnerability in extended crises, one we will examine in detail in Chapter 6.
Consider the difference between satisficing and giving up. A satisficing leader accepts a good-enough outcome intentionally, with continued monitoring. A depleted leader accepts whatever happens because they no longer have the capacity to evaluate. Can you think of a crisis example — from the news, from your own experience — where you suspect a leader crossed from satisficing to defaulting? What were the warning signs?
[short pause]
Understanding the cognitive science of crisis decision-making is valuable only if it translates into action. Drawing from the research reviewed in this chapter, several strategies emerge for leaders who must maintain decision quality under conditions designed to destroy it:
Reduce extraneous cognitive load ruthlessly. Every unnecessary piece of information, every avoidable interruption, every unresolved ambiguity consumes working memory. Crisis leaders must aggressively strip away non-essential demands — on themselves and their teams — to preserve capacity for the decisions that matter.
Build pattern libraries before the crisis. RPD only works if the patterns are already stored. Realistic scenario training, after-action reviews, case study analysis, and exposure to diverse crisis types all expand the library of recognizable situations. The time to build intuition is before you need it.
Designate a mode monitor. Assign someone on the team the explicit role of monitoring the decision process itself: Are we in the right mode? Are we analytically deliberating when we need to act? Are we pattern-matching when we should be questioning our assumptions? This metacognitive function is one of the first casualties of cognitive overload in the primary decision-maker.
Create structured pauses. Even in fast-moving crises, brief structured pauses — a ten-second "everyone stop and state what they see" — can interrupt fixation, surface missed information, and reset cognitive processes that have narrowed dangerously.
Accept satisficing explicitly. Make the satisficing threshold visible and stated: "We are looking for an action that prevents reactor breach for the next two hours. We are not looking for a permanent fix right now." Making the aspiration level explicit prevents both under-ambition and the paralyzing pursuit of perfection.
[short pause]
To summarize the key takeaways: Experienced professionals under time pressure do not compare options — they recognize patterns and mentally simulate a single course of action through Klein's RPD model, accounting for 80 to 90 percent of fireground decisions studied. Expert intuition is not mystical insight but compressed experience: a large library of encoded patterns that enables rapid situation categorization and action selection. Cognitive load degrades decision quality in sharp threshold drops, not gradual declines — leaders must actively manage load for themselves and their teams. Three decision modes — recognition-primed, analytical, and creative — serve different situations; the most dangerous errors occur from mode mismatch, particularly applying familiar patterns to genuinely novel situations. Satisficing — choosing good enough, fast enough — is the dominant strategy for crisis decision-making, but it requires cognitive resources that prolonged crises systematically erode. Practical strategies for protecting decision quality include reducing extraneous cognitive load, building pattern libraries through training, designating mode monitors, creating structured pauses, and making satisficing thresholds explicit.
[short pause]
In Chapter 4, we move from the individual decision-maker to the communication systems that connect crisis leaders to their teams and their publics. Even the best decision is worthless if it cannot be communicated clearly, quickly, and credibly. We will examine how crisis communication operates under the same constraints we explored here — time pressure, information degradation, and cognitive overload — and why the message received is almost never the message sent.












Who Needs to Know What, and When
In a crisis, information is both the most valuable resource and the most dangerous weapon. This chapter tackles stakeholder mapping and information hierarchy — the art of determining who needs what information, in what…
Your roommate's ex keeps texting asking where they are. How much do you tell them?
Moral dilemma
You overheard your friend's getting fired tomorrow. Do you give them a heads up tonight?
Would you warn them?
Would you rather: Get ten vague updates every 5 minutes OR one clear update after 30 minutes?
Pick one
Your family business is closing next month. Who deserves to know first: employees, regular customers, or family?
Who finds out first?
There are 47 unread messages in your group chat about some crisis. Be honest: do you scroll to the beginning or just read the latest ones?
Be honest
You can only warn ONE group about an incoming crisis: The people most at risk OR the people with power to fix it?
Impossible choice
Crisis Clock: Stakeholder Triage Under Pressure
12-15 minutesEach table receives a different crisis scenario (hospital outbreak, product recall, data breach, natural disaster). Teams have 3 minutes to list ALL possible stakeholders. Then the instructor announces time jumps: 'Hour 1: who MUST know right now?' (2 min), 'Hour 6: who becomes critical?' (2 min), 'Day 3: who emerges as unexpected priority?' (2 min). Teams write names on sticky notes and physically arrange them in priority order on their table. Instructor calls on 2-3 tables to defend their Hour 1 choices. Debrief focuses on how stakeholder salience shifts dramatically across crisis timeline.
Information Cascade Failure
15-18 minutesSet up a multi-layer information chain. Designate 3 tables as 'Field Teams' (collecting raw info), 3 as 'Regional Coordinators' (filtering/synthesizing), 3 as 'Crisis Command' (deciding/acting), and 1 as 'Executive Leadership' (communicating externally). Instructor feeds Field Teams conflicting, overwhelming information via slips of paper every 30 seconds for 3 minutes (mix of critical facts, rumors, irrelevant details). They must filter and pass up the chain. After 8 minutes total, Executive Leadership must brief the class on 'what happened.' Inevitably, critical info is lost or distorted. Debrief compares what Field Teams received vs. what Leadership reported, highlighting filtering failures.
Agency Coordination Breakdown Simulation
10-12 minutesAssign each table a different agency role in a shared crisis (Fire, Police, Hospital, Public Works, Media Relations, City Government, etc.). Each table receives unique information and objectives that create natural tensions. Give them 2 minutes to plan their agency's response. Then announce 'You must now coordinate' but provide NO coordination structure. Let chaos unfold for 4 minutes—teams try to shout updates across tables, some hoard information, priorities clash. Call time and ask: 'What went wrong?' Then give 2 minutes with ONE designated coordinator and simple reporting structure. Contrast the experiences.
Stakeholder Salience Shift: The Plot Twist
8-10 minutesEach table maps stakeholders for a crisis (using Power/Interest grid or Urgency/Legitimacy/Power framework on large paper). After 4 minutes, instructor introduces a 'plot twist' (e.g., 'Local activist group has video footage,' 'CEO's brother works for affected supplier,' 'Regulatory agency announces investigation'). Tables have 2 minutes to redraw their map with new reality. Gallery walk: half the tables stay to explain their shift, half circulate to see others' work (3 minutes), then switch. Debrief patterns: what kinds of events cause stakeholder importance to skyrocket?
Build the Filter: Information Hierarchy Design Challenge
12-15 minutesTeams compete to design the best information filtering system for a crisis scenario. They must create a visual flowchart showing: what info goes where, who decides what's escalated, what criteria trigger escalation, and how to prevent both information overload and critical gaps. After 7 minutes, teams post their designs. Do a 'silent gallery' where everyone walks around with sticky notes and flags: 1) potential failure points, 2) clever solutions they like. Instructor facilitates quick debrief highlighting common pitfalls (too many decision points, unclear escalation triggers, no feedback loops).
Rapid Stakeholder Role-Reversal Debate
10-12 minutesSelect a recent real crisis (instructor provides 1-page summary). Assign each table a stakeholder role (affected community, company, regulator, media, employee union, investors, etc.). Round 1 (3 min): Tables prepare their stakeholder's perspective on 'What information did we NEED and when did we need it?' Round 2 (5 min): Speed-dating debate format—on instructor's signal, one person from each table rotates to next table, argues their stakeholder perspective for 90 seconds, then rotates again. Rotating continues through 3 stations. Round 3 (3 min): Return to home table and discuss: 'What tensions did you discover? Where do stakeholder needs directly conflict?'
Transcript
On March twelfth, 2011, the hydrogen explosion at Fukushima Daiichi's Unit 1 reactor building was broadcast live on Japanese television. Prime Minister Naoto Kan watched the footage from his office in Tokyo, and it was the first he had learned of it. The plant operator, TEPCO, had not informed the government. The Nuclear and Industrial Safety Agency, the regulator supposedly overseeing the response, had no independent information about conditions inside the plant. For hours, national-level decision-makers debated evacuation zones and reassured the public based on assumptions that bore no relationship to what was actually happening at the reactor cores, as documented by Funabashi and Kitazawa in 2012.
This was not a failure of technology or intelligence. It was a failure of INFORMATION ARCHITECTURE, of not having answered the deceptively simple question at the heart of every crisis: who needs to know what, and when? That question, and the systems we build to answer it, is the subject of this chapter.
[short pause]
Beyond the Two-by-Two Grid: Dynamic Stakeholder Mapping
Most students of management or public policy will have encountered stakeholder mapping, the familiar exercise of plotting stakeholders on a two-by-two grid of power and interest, then tailoring engagement strategies accordingly. In calm conditions, this exercise is genuinely useful. In crisis, it can be dangerously misleading. The reason is simple: crisis fundamentally alters who matters.
The foundational work on stakeholder identification comes from Mitchell, Agle, and Wood, who argued in 1997 that STAKEHOLDER SALIENCE, the degree to which managers give priority to competing stakeholder claims, depends on three attributes: power, the stakeholder's ability to impose its will; legitimacy, the perceived appropriateness of the stakeholder's claim; and urgency, the time-sensitivity and criticality of the stakeholder's claim. Stakeholders possessing all three attributes are definitive and demand immediate attention. Those possessing only one are latent, they exist in the background, often unnoticed.
Here is what makes crisis so disorienting for leaders: crisis reshuffles these attributes with extraordinary speed. As Alpaslan, Green, and Mitroff demonstrated in 2009, dormant stakeholders, those possessing power but lacking legitimacy or urgency in normal operations, can become dangerous and definitive overnight. Consider the families of victims. In routine operations, they are not stakeholders at all. The moment a crisis produces casualties, they become among the most legitimate, most urgent, and through media amplification, most powerful stakeholders in the entire system. A community group that a corporation has routinely ignored may suddenly hold the keys to the organisation's social license to operate. A mid-level regulator whom senior leaders have never met may become the person whose sign-off is needed before any remediation can begin.
Conversely, people who normally hold definitive authority can find their salience evaporating. As Boin, 't Hart, Stern, and Sundelius documented in 2017, formal hierarchies are routinely bypassed during crisis, with information and decision authority flowing to whoever happens to be closest to the problem, most trusted by the media, or most politically convenient. A CEO who is definitive in normal operations may become irrelevant if the crisis is technical and they lack expertise, or if the crisis is political and a government minister takes over the narrative.
[short pause]
The Temporal Dimension: Stakeholder Salience Shifts Through Phases
What makes dynamic stakeholder mapping even more challenging is that salience does not shift once and stabilise. It shifts continuously as the crisis evolves through phases. In the initial hours, operational responders, fire crews, medical teams, on-site engineers, are the definitive stakeholders. They need information immediately, at high fidelity, and without distortion. By the escalation phase, external agencies, political actors, and media outlets have entered the picture, and the information needs diversify dramatically. By the time public attention peaks, the families, community advocates, and opposition politicians who were entirely absent from the initial response may be driving the narrative.
This is why static stakeholder maps fail in crisis. A map drawn in hour one is obsolete by hour six. Leaders who do not actively reassess stakeholder salience as the crisis evolves will find themselves directing information at the wrong people and ignoring the people who now matter most.
[short pause]
Consider a major data breach at a financial institution. Who are the definitive stakeholders in the first hour? Who becomes definitive by day three, when the story reaches national media? Who might be entirely absent from the initial stakeholder map but becomes central by week two? Think about how power, legitimacy, and urgency shift for each group across these timeframes.
[short pause]
Information Hierarchy: Matching Fidelity to Authority
Once you know who your stakeholders are and how their salience shifts, the next challenge is determining what information each stakeholder needs. This is the problem of INFORMATION HIERARCHY, the deliberate structuring of who receives what information, at what level of detail, through which channels, and in what sequence.
The instinct of many leaders, particularly in transparent and democratic cultures, is that everyone should get all the information. This instinct is well-meaning and catastrophically wrong. Recall from Chapter 3 that COGNITIVE LOAD theory tells us the human working memory can only process a limited amount of novel information simultaneously. Every piece of information routed to a decision-maker either supports or degrades their capacity to decide. A minister who receives raw technical telemetry data from a nuclear plant is not better informed, they are overwhelmed and less capable of making the political decisions that are actually within their authority.
The principle that should govern information hierarchy is information fidelity matched to decision authority. The incident commander at a disaster site needs granular, real-time, technical data because they are making operational decisions that depend on that data. The executive leadership team needs synthesised situation reports because they are making strategic decisions about resource allocation and organisational positioning. The minister's office needs headline-level summaries with political implications highlighted because they are making decisions about public communication and policy response. The families of affected people need accurate, compassionate, timely updates because their decisions are about whether to trust the organisation managing the crisis.
[short pause]
The Filtering Problem
Between the raw information generated at the crisis point and the synthesised summaries that reach senior leaders lies a chain of information filtering. At every node in that chain, someone is deciding what to pass up, what to push down, what to hold, and what to discard. This filtering is essential. Without it, senior decision-makers would drown in noise. But filtering introduces risk.
The Grenfell Tower fire of 2017 illustrates what happens when filtering goes wrong. The Phase 1 report of the Grenfell Tower Inquiry documented in 2019 that the London Fire Brigade, the Metropolitan Police, and the London Ambulance Service each operated with different situational pictures because there was no shared information hierarchy. Fire control room operators received calls from residents trapped on upper floors but this critical intelligence, which directly contradicted the operational assumption that residents should stay put, was not systematically routed to the incident commander on scene. The information existed within the system. The filtering architecture failed to move it to the people who needed it for the decisions they were making.
Comes, Hiete, Wijngaards, and Schultmann add an important nuance in 2022: the people doing the filtering are themselves subject to the cognitive biases we discussed in Chapter 3. Their experimental research demonstrated that crisis managers are prone to significant confirmation bias when selecting which information to pass upward. They preferentially route information that confirms the existing operational picture and deprioritise information that contradicts it. Under high cognitive load, this bias intensifies. The result is that precisely the information most likely to change a leader's decision, the disconfirming signal, the unexpected data point, the report that the situation is worse than assumed, is the information most likely to be filtered out.
[short pause]
Imagine you are the operations section chief during a crisis. You receive a report from the field that directly contradicts the working assumption your incident commander is using to make decisions. The report comes from a single source and seems implausible. Do you pass it up immediately, disrupting the current decision cycle? Hold it until you can verify? Or filter it out as likely erroneous? What factors would change your decision?
[short pause]
Multi-Agency Coordination: When Organisations Collide
The challenges of stakeholder mapping and information hierarchy become exponentially more complex when a crisis requires coordination across multiple organisations. This is the norm, not the exception. Almost every significant crisis, from bushfires to pandemics to terrorist attacks, demands coordinated action by agencies that do not normally work together, do not share terminology, do not use compatible communication systems, and carry fundamentally different assumptions about who is in charge.
Bharosa, Lee, and Janssen conducted systematic research on multi-agency disaster response exercises in 2010 and identified information sharing as the single greatest bottleneck in inter-agency coordination. Their findings documented a cascade of challenges: different agencies use different data formats, different classification systems, different communication protocols, and different organisational cultures around information security. A fire service that operates on a principle of share everything fast collides with a police service that operates on need to know. A health authority that communicates in clinical precision encounters a local government that communicates in bureaucratic circumlocution.
[short pause]
The Terminology Problem
One of the most insidious coordination failures is terminology mismatch, the phenomenon where different agencies use the same words to mean different things, or different words to mean the same thing. Ackerman, Wulf, Pipek, and Randall documented this extensively in 2014 in their study of inter-organisational crisis management, finding that even organisations operating within the same country and the same broad sector carried distinct vocabularies that created dangerous miscommunication under pressure.
During Australia's Black Summer bushfires of 2019 to 2020, fire agencies across different states used different warning level systems, different terminology for evacuation categories, and different protocols for requesting interstate assistance. The phrase watch and act carried different implications in different jurisdictions. Controlled could mean the fire was contained, or merely that resources were being applied, a potentially lethal ambiguity for a community deciding whether to evacuate. These are not academic distinctions. When information hierarchy crosses organisational boundaries, terminology alignment becomes a matter of life and death.
[short pause]
The Authority Problem
Beyond terminology lies the deeper problem of authority confusion. Boin and colleagues describe in 2017 the crisis of governance that emerges when multiple organisations, each with legitimate authority over some aspect of the response, must coordinate without a clear overarching command structure. Who is in charge of a crisis that is simultaneously a public health emergency, health authority, a law enforcement matter, police, an environmental disaster, environmental agency, and a political crisis, elected officials?
The Grenfell Tower response illustrated this with tragic clarity. The London Fire Brigade assumed it was the lead agency and that police and ambulance services would support its operational plan. The Metropolitan Police, however, had its own operational priorities around evidence preservation and witness management. The London Ambulance Service needed access to information about which floors were survivable to triage its response. Each organisation operated on its own institutional assumptions about information flow and decision authority, and there was no mechanism to reconcile these assumptions in real time, as documented in the Phase 1 report in 2019.
[short pause]
Information Filtering: Protection or Blind Spot?
We return now to the filtering problem introduced earlier, because it requires one final, critical distinction. Information filtering in crisis exists on a spectrum between two poles: PROTECTIVE FILTERING, which shields decision-makers from noise so they can focus on signal, and PATHOLOGICAL FILTERING, which creates blind spots that disconnect leaders from reality.
Protective filtering is what allows a minister to make sound decisions during a crisis without being paralysed by data. It is the intelligence cell that synthesises forty field reports into a coherent situation assessment. It is the public affairs officer who shields the incident commander from media inquiries so they can focus on operations. It is the executive assistant who holds all but the most critical calls. Without protective filtering, the cognitive load on senior decision-makers would make effective leadership impossible.
Pathological filtering is what happened at Fukushima. TEPCO's internal culture created what Funabashi and Kitazawa describe in 2012 as an information silo in which critical technical data about reactor core conditions was trapped within the plant operator's hierarchy. The national government was not merely receiving filtered information, it was receiving a filtered picture that systematically excluded the most alarming data. The filtering was pathological because it did not serve the decision needs of the people it was shielding; it served the institutional interests of the people doing the filtering.
How do you tell the difference? Three diagnostic questions help. First, who benefits from the filtering? If the filtering serves the decision-maker by reducing noise, it is protective. If it serves the filter by avoiding difficult conversations, it is pathological. Second, is disconfirming information getting through? If the information reaching decision-makers consistently confirms the existing operational picture, the filtering system should be treated as suspect. As we learned in Chapter 3, the absence of bad news is not the same as the presence of good news. Third, can the decision-maker pull information when needed? Protective filtering allows leaders to request deeper detail on any topic. Pathological filtering creates structures where lower levels actively resist sharing information upward, even when asked.
[short pause]
Reflect on an organisation you have worked in or studied. What were the information filtering norms? Who decided what information reached senior leadership? Were there mechanisms for disconfirming information to bypass the normal filtering chain? If a frontline worker knew something critically important that contradicted the organisation's official narrative, what would happen to that information?
[short pause]
Building the Information Architecture Before the Crisis
The central lesson of this chapter is that information architecture cannot be improvised during a crisis. By the time you are asking who needs to know this in the middle of an unfolding disaster, you have already lost critical time. Research by Bharosa and colleagues in 2010 found that the organisations that performed best in multi-agency exercises were those that had established information-sharing protocols, common terminology glossaries, and pre-agreed escalation pathways before the crisis occurred.
This does not mean creating rigid, bureaucratic protocols that cannot adapt. It means establishing three things: a stakeholder map that has been stress-tested against crisis scenarios and updated regularly; an information hierarchy that specifies what level of detail each node in the response structure needs and has the authority to act on; and coordination agreements with partner agencies that resolve terminology, authority, and communication protocol conflicts before those conflicts matter.
The relationship between this chapter and the communication chapter that follows is deliberate. You cannot communicate effectively if you have not first worked out the information architecture. Communication is the outward expression of decisions about audience, message, channel, and timing, but those decisions depend entirely on the stakeholder mapping, information hierarchy, and coordination structures we have examined here. Get the architecture right, and communication becomes a matter of execution. Get the architecture wrong, and no amount of polished messaging will prevent the chaos that results.
[short pause]
Key Takeaways
Let me summarise the key points from this chapter. First, stakeholder salience is dynamic in crisis. Power, legitimacy, and urgency shift continuously, making static stakeholder maps dangerously misleading. Second, dormant stakeholders, those with latent power but no current legitimacy or urgency, can become definitive overnight during a crisis, while previously authoritative actors may lose relevance. Third, information hierarchy should match information fidelity to decision authority. Operational leaders need granular data, strategic leaders need synthesised assessments, and political leaders need implication summaries. Fourth, information filtering is essential but carries inherent risk, particularly the risk that disconfirming information is disproportionately filtered out due to confirmation bias under cognitive load. Fifth, multi-agency coordination fails most often at three points: terminology mismatches, information gaps between agencies, and conflicting assumptions about decision-making authority. And finally, information architecture must be designed, tested, and refined before a crisis occurs. It cannot be improvised under pressure.
[short pause]
Looking Ahead
With the information architecture established, Chapter 5 turns to what most people think of when they hear crisis communication, the public-facing dimension. How do you communicate with stakeholders, the media, and the public when information is incomplete, the situation is evolving, and every word you say will be scrutinised? We will discover that the principles of stakeholder mapping and information hierarchy from this chapter are the invisible scaffolding on which all effective crisis communication is built.













Speaking into the Void
In a crisis, you will almost certainly have to say something before you know what is happening. This chapter confronts the hardest communication challenge in leadership: speaking publicly when the information is…
What's worse: getting pinged every day with 'still no update' messages during a crisis, or complete radio silence until they figure it out?
What's worse
Would you rather: Company admits 'we have no idea what went wrong' immediately, OR waits 3 days to give you the full story?
Would you rather
Have you ever completely stopped trusting a brand because of how they handled a crisis? What killed it for you?
Real talk
You're the CEO. Your product just harmed someone but you don't know why yet. Do you post about it today or wait until you have actual answers?
You're the CEO
Should employees find out about company disasters before customers do, or is everyone finding out at the same time more fair?
Who hears first
A fake-sounding corporate apology is better than no apology at all. Agree or disagree?
Unpopular opinion?
The 72-Hour Crisis Simulation
15-20 minutesEach table receives the same crisis scenario (e.g., product recall, data breach) but different time stamps: Hour 2, Hour 12, Hour 24, Hour 48, Hour 72. Teams draft the appropriate public update for their assigned moment. After 8 minutes, one spokesperson from each table stands and delivers their message in chronological order. Class observes how transparency, tone, and information evolve—and votes on which updates maintain vs. erode trust.
Dual Message Dilemma
12-15 minutesTeams receive a crisis brief and must simultaneously draft two messages: one for internal employees and one for external customers—both addressing the same event. After 7 minutes, adjacent tables swap their message pairs. Tables identify discrepancies, contradictions, or tone mismatches that could create credibility problems if both leaked. Teams present their findings: 'Here's how this organization would get caught in inconsistency.'
The Uncertainty Spectrum
10-12 minutesPresent a crisis scenario where facts are still emerging (e.g., cause of outage unknown, investigation ongoing). Each table must craft a public statement choosing a position on the transparency spectrum: (1) Maximum disclosure of uncertainty, (2) Moderate disclosure with reassurance, (3) Minimal disclosure with action focus. Tables post statements on the wall. Class does a gallery walk, then votes: which approach maintains credibility AND manages anxiety? Debrief by discussing when each strategy might be appropriate.
Empathy Audit Speed Round
8-10 minutesDisplay 4-5 real crisis messages (from actual companies/organizations, anonymized). Each table gets 90 seconds per message to score it on two axes: Empathy (1-10) and Transparency (1-10). Tables record scores on a shared digital board or whiteboard grid. Rapid-fire discussion: Why did we all rate Message 3 high on transparency but low on empathy? What's missing? Instructor highlights patterns and surprises in the scoring.
Stakeholder Carousel
12-15 minutesEach table is assigned a stakeholder identity (employees, customers, investors, regulators, media, community members). Present a crisis scenario. Round 1 (3 min): Draft what YOUR stakeholder needs to hear. Round 2 (6 min): Two students from each table rotate to a new table, bringing their stakeholder perspective. Tables now try to craft a SINGLE message that addresses all represented stakeholders. Round 3: Share the impossible trade-offs discovered. Discussion: When is unified messaging possible? When do you need separate channels?
The Silent Update Challenge
10-12 minutesPresent a multi-day crisis timeline. One team member from each table is designated the 'communication lead.' Crisis unfolds in real-time via instructor announcements (new info every 90 seconds). Communication leads must decide: Issue update now, or wait? Each time they issue an update, they stand and state it aloud (15 seconds max). Other teams track: Who updated when? Who stayed silent? After timeline ends, analyze: Which cadence maintained trust? When did silence become suspicious? When did over-updating seem panicky?
Transcript
It is three forty-seven a.m. Your phone is ringing. There has been an explosion at one of your organisation's facilities. Early reports mention casualties — two confirmed dead, possibly more. The cause is unknown. Social media is already alive with shaky video footage, and a local news crew is parked at the perimeter. A reporter calls your communications director. "We're going live at the top of the hour. Do you have a statement?" You have forty-three minutes. You do not know if the explosion was accidental, structural, or something worse. You do not know the final casualty count. You do not know whether the site is safe. But you know this with absolute certainty: if you say nothing, someone else will fill the silence — and they will fill it with speculation, fear, and blame.
Welcome to the void. This is about learning to speak into it.
[short pause]
Every instinct in a careful, legally trained, risk-averse leader screams the same thing during a crisis: wait. Wait until the facts are confirmed. Wait until legal has reviewed the statement. Wait until the investigation team reports back. The impulse is understandable. It is also catastrophic.
The foundational insight of modern crisis communication research is that stakeholders do not wait for you to be ready. As Sellnow and colleagues demonstrated in 2016 in their systematic review of crisis uncertainty communication, crises create a unique paradox: the moments when organisations have the least information are precisely the moments when the demand for communication is at its peak. Base knowledge is incomplete, yet the public, the media, and your own employees require communication immediately — not when it is convenient.
W. Timothy Coombs's Situational Crisis Communication Theory, known as S-C-C-T, provides the theoretical architecture for understanding why this matters. S-C-C-T establishes that post-crisis communication is not merely informational — it is reputational and relational, as Coombs established in 2007. The way you communicate in the first hours doesn't just convey facts; it signals what kind of organisation you are. Are you accountable or evasive? Do you care about people or about liability? Every hour of silence answers those questions for you, and never in your favour.
The reason is simple but important to internalise: silence in a crisis is never interpreted as "nothing to report." It is interpreted as "they are hiding something." This asymmetry — between the leader's intention of caution and the public's interpretation of concealment — is the central challenge we need to address.
Consider this: Recall a recent crisis in the news where an organisation was criticised for its communication. Was the criticism primarily about what they said — or about how long they waited to say it?
[short pause]
Before we extract principles, we need to study wreckage. The three cases that follow represent different failure modes in crisis communication. Each eroded public trust through a distinct mechanism, and together they map the full terrain of what can go wrong when leaders speak — or fail to speak — during a crisis.
When the Tōhoku earthquake and tsunami struck Japan on the eleventh of March, 2011, the Fukushima Daiichi nuclear power plant lost power and began a catastrophic meltdown sequence. What followed was not merely a nuclear disaster but a communication disaster of historic proportions. As Funabashi and Kitazawa documented in 2012 in their independent investigation, TEPCO — the plant's operator — and the Japanese government engaged in a pattern of communication that moved from delay to evasion to outright concealment.
The meltdown of Reactor 1 began on the first day. TEPCO did not publicly acknowledge it for over two months. In the intervening period, public statements were characterised by technical jargon designed to obscure rather than clarify, contradictions between government and company spokespeople, and a persistent refusal to use the word "meltdown" even when the physical reality was undeniable. The government, for its part, made no effective effort to educate the public about radiation levels or explain what evacuation zones meant in practical terms.
The mechanism of trust destruction here was incremental credibility erosion. Each statement that was later contradicted by events did not merely damage trust in that specific statement — it retroactively poisoned every previous statement. By week three, TEPCO could have issued a perfectly accurate, perfectly transparent update and it would not have been believed. The lesson is stark: once you have been caught understating a crisis, your audience assumes you are still understating it.
[short pause]
On the fourteenth of June, 2017, Grenfell Tower in west London caught fire, killing seventy-two people. The Phase 1 Report of the Grenfell Tower Inquiry, led by Moore-Bick in 2019, documented communication failures at every level. Internally, the fire service's communication links were so degraded that neither the control room nor the incident commanders knew whether rescue attempts on upper floors had been made — or what their outcomes were. Externally, the local council's response was described as emotionally tone-deaf, bureaucratically rigid, and agonisingly slow.
But the most damaging failure was structural: no single entity owned the public communication. Bereaved families received contradictory information about where to seek help, whether their loved ones had survived, and what the council would do for them. Volunteer organisations were not coordinated. The result was a communication vacuum — a space where information should have existed but didn't — which was rapidly filled by grief, rumour, and rage.
Where Fukushima demonstrated the cost of saying the wrong thing, Grenfell demonstrated the cost of failing to say anything at all. The absence of a clear, empathetic, authoritative voice left families to interpret institutional silence as institutional indifference — and in many cases, that interpretation was correct.
[short pause]
The airline industry has produced some of crisis communication's sharpest lessons. As Ray documented in 1999, there are cases where technically precise statements — factually accurate, legally vetted, operationally sound — landed with the public as cold, mechanical, and inhuman. An airline might issue a statement confirming that "an incident involving flight such-and-such occurred at such-and-such time" while families were desperately trying to learn whether their loved ones were alive.
The failure mode here is different from Fukushima's evasion or Grenfell's vacuum. It is a failure of REGISTER — the emotional key in which a message is delivered. The information was often accurate, but it was delivered in the language of operations rather than the language of human concern. As Schoofs and colleagues demonstrated experimentally in 2019, stakeholder empathy is not a soft, optional dimension of crisis response — it is a critical mechanism through which reputational outcomes are determined. Their three studies show that when organisations communicate in ways that evoke empathy, the reputational damage of even severe crises is significantly reduced.
Three distinct failure modes in crisis communication — evasion, vacuum, and wrong register — all converge on the same outcome: the destruction of public trust.
[short pause]
On the twenty-third of June, 2018, twelve boys and their football coach entered the Tham Luang cave complex in northern Thailand. Rising floodwaters trapped them. What followed was a seventeen-day international rescue operation conducted under the glare of a global media siege, with thousands of journalists from dozens of countries camped outside the cave.
The communication strategy was, by all accounts, extraordinary in its discipline. Analysis of the response, published in 2018, identifies several key features: regular press briefings were held regardless of whether there was new information to share; the messaging was consistent, with no conflicting statements despite dozens of agencies being involved; families were given direct, private channels of communication including handwritten notes between them and the trapped boys; and setbacks — including the death of a former Thai Navy SEAL diver — were confirmed promptly and with appropriate gravity.
What made the Thai cave rescue communication work was not that the communicators had more information than TEPCO or the Grenfell authorities. They often had very little. What they had was a communication ARCHITECTURE — a deliberate system that governed who spoke, when, to whom, and in what register. That architecture rested on three principles that we can now extract and formalise.
Think about this for a moment: The Thai cave rescue team held press briefings even when they had no new information to report. Why might a briefing with no news be more valuable than no briefing at all? What does the act of showing up communicate, independent of content?
[short pause]
The first principle is EMPATHY FIRST. Before your audience processes a single fact in your statement, they have already answered one question: does this person care about what we're going through? If the answer is no — or even uncertain — nothing that follows will land correctly. Schoofs and colleagues in 2019 provide the experimental evidence: empathy is not a rhetorical nicety but a cognitive gateway. It determines whether subsequent information is processed as trustworthy or defensive.
In practice, empathy first means that the opening of any crisis statement must acknowledge the human reality before addressing the operational situation. "Our thoughts are with the families and all those affected" is not a cliché if it is followed by concrete evidence of care — what you are doing for them, what resources are available, where they can go. It becomes a cliché when it substitutes for action, or when it is immediately followed by legal hedging.
The question to ask yourself before every crisis communication is: What are people feeling and fearing right now? Your first sentences should demonstrate that you know the answer.
[short pause]
The second principle is TRANSPARENCY ABOUT UNCERTAINTY. This is the principle that most leaders find counterintuitive, and it is the one that the research most strongly supports. Sellnow and colleagues established in 2016 that acknowledging uncertainty — openly stating what you do not know — does not erode credibility. Concealing uncertainty erodes credibility. The formula is deceptively simple: say what you know, say what you don't know, and say when you expect to know more.
"We can confirm that an explosion occurred at our facility at approximately three fifteen a.m. We can confirm that emergency services are on site. We cannot yet confirm the cause of the explosion, and we cannot yet confirm the number of people affected. We expect to have more information within the next two hours, and we will update you at that time." That statement contains almost no information. It is, nonetheless, a far more effective crisis communication than silence, evasion, or premature certainty — because it gives the audience a framework for understanding the situation and a reason to wait for the next update rather than seek answers elsewhere.
[short pause]
The third principle is UPDATE CADENCE. The Thai cave rescue's most underappreciated innovation was its update cadence — the regular rhythm of communication events that gave the media and public a predictable pattern to anchor to. This matters because the rhythm of communication is as important as its content. A twelve-hour gap between updates, even if justified by the pace of events, creates a twelve-hour window in which speculation replaces information.
Cadence serves three functions. First, it pre-empts the "why aren't they saying anything?" narrative. Second, it creates a Pavlovian expectation — journalists and the public learn to wait for the next scheduled update rather than filling the gap. Third, it gives the communicating team a structure that reduces the cognitive load of deciding when to communicate, freeing them to focus on what to communicate.
The appropriate cadence depends on the crisis phase. In the acute phase — the first six to twelve hours — updates may need to come every thirty to sixty minutes. In the sustained phase, every four to six hours. In the recovery phase, daily. The key is that the cadence must be announced and kept. A missed update is worse than a content-free update.
[short pause]
Trust in a crisis is not binary — it is a resource that depletes and sometimes replenishes based on the pattern of communication decisions over time. Think of it as a bank account that you did not know you had until the crisis began. Every honest update is a small deposit. Every evasion, delay, or contradiction is a large withdrawal. And the exchange rate is deeply unfair: it takes ten deposits to recover from one significant withdrawal.
This metaphor becomes operationally important when you recognise that different stakeholder groups maintain separate trust accounts. The public's trust in your organisation, the media's trust in your spokesperson, affected families' trust in your commitment to them, and your own staff's trust in leadership — these are four different accounts with different balances, different sensitivities, and different triggers for collapse. The Thai cave rescue succeeded in part because the communication architecture addressed each group through dedicated channels: press briefings for media, private notes for families, operational briefings for the multi-agency team.
Coombs formalised this insight in 2007 in S-C-C-T by demonstrating that the appropriate communication strategy must be matched not just to the crisis type but to the attribution of responsibility that each stakeholder group applies. If your stakeholders believe you caused the crisis, empathetic, accommodative responses protect reputation. If the crisis is seen as externally caused, informational responses suffice. Misjudging the attribution — communicating as though you are a victim when your audience holds you responsible — is one of the fastest routes to trust destruction.
[short pause]
Every crisis communication leader faces a problem that is rarely discussed in public accounts of crisis response: you are always speaking to at least two audiences simultaneously, and what each audience needs is different — sometimes contradictory.
Your external communication — press statements, social media updates, press conferences — must be empathetic, measured, legally careful, and accessible to a general audience. Your internal communication — messages to your own staff, operational teams, and middle management — must be operationally specific, emotionally honest, and free of the corporate hedging that, while appropriate for external audiences, destroys trust when directed at the people doing the work.
Research on internal crisis communication from 2024 demonstrates that transparent, timely communication during crises helps employees feel supported and engaged, reduces uncertainty, and maintains the morale essential for sustained operations. When internal communication fails — when staff learn about developments from the news rather than from their own leadership, or when internal messages use the same sanitised language as press releases — the consequences extend beyond morale. Information flow degrades. Staff who do not trust leadership stop reporting problems upward, precisely when accurate upward information flow is most critical. This connects directly to the information hierarchy challenges we examined in the previous chapter.
The trap, however, is inconsistency. In our hyper-connected world, the distinction between internal and external communication is porous. Staff share internal emails. Screenshots leak. If your internal message says "this is serious and we are deeply concerned" while your external statement says "we are confident the situation is under control," you have created a coherence gap — and when that gap becomes public, it destroys trust with both audiences simultaneously.
The discipline, therefore, is to draft internal and external messages that are different in register and detail but consistent in substance. Your staff need more operational specificity and less legal hedging. The public needs less jargon and more actionable guidance. But both messages must be defensible if the other were read alongside it.
Consider this question: Imagine an internal email you wrote to your team during a crisis was published on the front page of a newspaper. What would you need to change — and what should you have written differently from the start to survive that test?
[short pause]
From the cases and principles we've examined, we can distil an operational checklist for any crisis communication. Before issuing any public or internal statement, a crisis leader should verify the following:
Empathy gate: Do the first two sentences acknowledge the human reality of what is happening?
Known-unknown structure: Does the statement clearly separate confirmed facts from unconfirmed reports?
Next-update commitment: Does it state when the audience will hear from you again?
Actionability: Does it tell affected people what to do right now?
Legal review: Has it been checked for promises you cannot keep and admissions you are not authorised to make?
Coherence check: If your internal and external messages were read side by side, would they tell a consistent story?
Audience calibration: Is the register appropriate — operational detail for staff, plain language for public?
This checklist does not guarantee a perfect crisis communication. No checklist can. But it ensures that you avoid the failure modes that destroyed trust at Fukushima, Grenfell, and in the airline cases we examined — and that you build the communication architecture that sustained trust during the Thai cave rescue.
[short pause]
To summarise the key insights: Silence during a crisis is never neutral — it is interpreted as concealment, evasion, or indifference, regardless of the leader's intent. Empathy is not a rhetorical flourish but a cognitive gateway: audiences decide whether to trust your information based on whether they believe you care about their experience. Transparency about uncertainty — stating what you know, what you don't, and when you'll know more — builds credibility more effectively than waiting for complete information. Update cadence is a structural tool: the regular rhythm of communication pre-empts speculation, manages expectations, and reduces the cognitive load on the communication team. Internal and external crisis messages must differ in register and detail but remain consistent in substance — because in practice, the wall between them is always permeable. And finally, trust erodes asymmetrically: a single evasion or contradiction costs more credibility than ten honest updates can rebuild.
[short pause]
You now understand how to communicate during a crisis. But what happens to the teams who must sustain crisis operations not for hours but for days, weeks, or months? The next chapter examines team resilience during prolonged crisis operations — how fatigue degrades decision-making, how leaders maintain morale when there is no end in sight, and why the communication practices you've learned here are essential to keeping your people functional when the crisis refuses to end.













The Long Night
Some crises end in minutes. The ones that break organisations — and the people in them — last days, weeks, or months. This chapter examines what happens to leaders, teams, and decision-making when the crisis refuses to…
Would you rather: Work one brutal 16-hour shift, or two 8-hour shifts where the handoff is a total disaster and you lose half the information?
Would you rather
Hot take: Making important decisions when you're exhausted is basically the same as making them drunk. Agree or nah?
Hot take
You've been awake for 20 hours and still have a critical decision to make. Do you power through, or hand it off to someone fresh who knows way less than you?
Real talk
What's worse: A well-rested amateur or an exhausted expert?
Debate time
Be honest: How many hours into an all-nighter before you're just moving the same words around and calling it progress?
Quick poll
Should there be a legal limit on how many consecutive hours someone can work before they're not allowed to make life-or-death decisions?
Unpopular opinion?
The Degrading Decision Exercise
15-18 minutesRound 1 (5 min): Teams receive a complex operational scenario and make a decision together. Round 2 (4 min): Same type of scenario, but now with 20% less time and one team member must remain silent ('fatigue effect'). Round 3 (3 min): Another scenario with even less time, two members silent, and one critical piece of information withheld. Debrief (5 min): Teams reflect on how decision quality changed and what shortcuts they took under pressure. Instructor facilitates whole-class discussion on patterns observed.
The Shift Handover Challenge
12-15 minutesPair adjacent tables. Table A ('outgoing shift') receives a complex ongoing scenario and manages it for 5 minutes, taking notes on their approach. They then have exactly 2 minutes to handover to Table B ('incoming shift'). Table B continues managing the scenario for 3 minutes without asking follow-up questions. Debrief (4 min): Both tables discuss what information was lost, what assumptions were made, and what went well. Instructor highlights common handover failures observed across the room.
Leader in the Hot Seat
12-15 minutesEach table selects one person as their 'night shift leader.' For 6 minutes, the remaining team members role-play as direct reports who continuously bring problems, requests for decisions, and conflicting information to their leader. Leader must manage their own stress, prioritize decisions, and maintain team morale while being bombarded. Rotate halfway through so another person experiences the hot seat (3 min each). Debrief (6 min): Leaders share what strategies they used (or wish they'd used) for self-management. Class identifies patterns of leader degradation.
The 3 AM Test
14-16 minutesGive half the tables (Team Day) a case to solve under normal conditions: full information, adequate time (6 min). Give the other half (Team Night) the EXACT SAME case but under degraded conditions: two pieces of information missing, 4 minutes only, and they must whisper (simulating low energy). All teams prepare solutions. Then compare: Team Day tables share their solutions (3 min), followed by Team Night tables (3 min). Debrief (4 min): Discuss differences in solution quality, what corners Team Night cut, and what protocols could help.
Resilience Protocol Speed Build
16-18 minutesPhase 1 (5 min): Each table brainstorms 3-5 practical protocols for maintaining team resilience during prolonged operations (e.g., mandatory breaks, buddy checks, rotation schedules). Phase 2 (6 min): Each table sends two 'ambassadors' to visit two other tables, learn their protocols, and return. Ambassadors tour while one person stays to explain their table's work. Phase 3 (4 min): Tables integrate best ideas from others and revise their protocols. Phase 4 (3 min): Quick gallery walk where everyone views final protocols on tables, or instructor spotlights 3-4 strong examples.
Handover Protocol Design & Live Test
18-20 minutesPhase 1 (6 min): Each table designs their ideal shift handover protocol (what must be communicated, in what order, what documentation, time required). Phase 2 (8 min): Pair tables. One table begins managing a complex scenario, then executes a handover to their partner table using their designed protocol. Partner table continues the operation. Phase 3 (6 min): Partner tables debrief together: What worked? What was missed? Was the protocol realistic under pressure? Instructor facilitates class discussion on common protocol elements that emerged.
Transcript
On the afternoon of June twenty-three, 2018, twelve boys from the Wild Boars football team and their coach entered the Tham Luang cave in northern Thailand. Within hours, monsoon rains flooded the entrance passages behind them. What followed was not a single dramatic rescue but seventeen days of continuous operations — a grinding, exhausting effort involving over ten thousand people, during which the initial adrenaline-fueled urgency slowly gave way to something far harder to sustain. By the eighth day, divers had located the boys alive on a muddy ledge four kilometers inside the mountain. The relief was enormous. But the hardest decisions still lay ahead, and the people who would make them had already been working for over a week without meaningful rest.
[short pause]
The Thai cave rescue is a study in what happens when crisis demands outrun human endurance. Several of the international cave divers later described moments of impaired judgment during the operation — small errors in equipment checks, slowness in processing new information, a creeping rigidity in thinking that they recognized, with alarm, as the early signatures of fatigue. One diver, Richard Harris, an anesthetist who would sedate each boy for the underwater extraction, had been awake for most of the preceding forty-eight hours when he administered the first dose. He later acknowledged that the decision to proceed relied as much on the team structure around him — the checks, the redundancy, the people willing to say "stop" — as on his own clinical judgment. The crisis did not care that everyone was tired.
[short pause]
Every crisis begins with mobilization. The alarm sounds, the team assembles, and a surge of neurochemical energy — cortisol, adrenaline, norepinephrine — sharpens attention, accelerates processing, and suppresses the body's signals for rest. In those first hours, decision-makers often report a sense of heightened clarity. Problems feel tractable. The team feels unified. There is an almost intoxicating sense of shared purpose.
This phase is real and physiologically grounded. But it is also temporary. Research on DECISION FATIGUE demonstrates that the quality of decisions degrades measurably after prolonged periods of cognitive effort, as studies from 2025 have shown. The decline is not dramatic — it is insidious. Decision-makers do not suddenly become incompetent. Instead, they begin taking shortcuts. They default to simpler heuristics. They become more risk-averse, choosing the safe option even when the situation demands boldness, according to research findings from 2022. And critically, they lose the metacognitive awareness to recognize that their judgment has changed.
[short pause]
The Fukushima Daiichi nuclear disaster illustrates this trajectory at scale. When the earthquake and tsunami struck on March eleven, 2011, the on-site response team at the plant worked with remarkable clarity under extraordinary pressure during the first twenty-four hours. Plant Superintendent Masao Yoshida made a series of bold, technically sound decisions — including defying orders from TEPCO headquarters to continue seawater injection into Reactor one. But as the crisis stretched into its second week, with multiple reactor buildings exploding and radiation levels climbing, the quality of coordination between the site team and external agencies visibly deteriorated. Communications became confused. Critical information was delayed or distorted. Decisions that should have taken minutes took hours, not because of bureaucratic obstruction but because the people making them were cognitively depleted.
[short pause]
To understand why prolonged crises break decision-making, we need to revisit the COGNITIVE LOAD framework introduced in Chapter four. WORKING MEMORY — the mental workspace where we hold, manipulate, and integrate information — has a finite and surprisingly small capacity, as Paas and van Merriënboer described in 2020. Under normal conditions, experienced professionals manage this limitation through expertise: well-rehearsed patterns and mental models reduce the load on working memory by packaging complex information into recognizable chunks.
Sustained stress disrupts this system at multiple levels. First, the stress response itself consumes working memory resources. The intrusive worries that accompany prolonged uncertainty — What if we're wrong? What are we missing? What happens if this fails? — occupy the same cognitive workspace needed for analytical thought, as Paas and van Merriënboer noted. Second, sleep deprivation and physical exhaustion degrade the prefrontal cortex functions that support executive control, the very capacities that distinguish expert judgment from reactive impulse. Third, and perhaps most dangerously, cumulative fatigue erodes the capacity for MENTAL SIMULATION — the ability to project a course of action forward and evaluate its likely consequences before committing to it.
[short pause]
The answer, supported by Klein's own research and subsequent experimental work, according to research spanning from 1989 to 2004, is that mental simulation degrades first. Pattern matching is relatively automatic in experienced professionals — it draws on deeply encoded long-term memory and requires less active working memory. Mental simulation, however, demands sustained, effortful processing: you must hold the proposed action in mind, project it forward through multiple steps, and evaluate the outcome against your goals. This is exactly the kind of cognitive work that fatigue undermines. The result is a dangerous condition where experienced professionals continue to recognize patterns correctly — they still feel like they know what is going on — but they lose the ability to critically evaluate whether their proposed response actually fits the evolving situation. They match to the right pattern from yesterday while failing to notice that conditions changed overnight.
[short pause]
If fatigue degrades decision quality so predictably, why do experienced leaders consistently fail to rest during prolonged crises? The answer lies in a convergence of psychological, social, and organizational pressures that create what we might call the INDISPENSABILITY TRAP.
During the 2019 to 2020 Australian Black Summer bushfire season — five months of relentless escalation across multiple states — Rural Fire Service volunteer captains and incident controllers routinely worked sixteen to twenty hour days for weeks on end. Many later described feeling that stepping away, even for a few hours, would constitute a kind of abandonment. "If my crew is out there," one captain recalled, "I should be in the control room." The feeling was genuine, deeply held, and profoundly counterproductive.
Research on burnout in emergency response environments reveals that this pattern is not a character flaw but a predictable system failure, as Uccheddu and colleagues found in 2025. Burnout rates among emergency professionals exceed seventy percent in some high-demand settings, driven by workload, inadequate rest, and the emotional burden of sustained responsibility. The same qualities that make someone an effective crisis leader — commitment, ownership, accountability — become liabilities when they prevent the leader from recognizing their own impairment.
VanSlyke, Brunell, and Simons examined this dynamic during the COVID-19 pandemic in 2020, observing that leaders who thrived during temporary crises often struggled during prolonged ones precisely because they treated every phase with the same intensity as the opening hours. Their ADAPTIVE CAPACITY — the ability to modulate effort across time — was poorly developed. The researchers emphasized that sustainable crisis leadership requires leaders to model self-care, appoint trusted deputies, and create the psychological safety necessary for team members to say, without penalty, "I need to step back."
[short pause]
The challenge is that cognitive fatigue actively undermines the self-monitoring capacity you need to detect cognitive fatigue. This is not a paradox — it is a design feature of the human brain. The prefrontal cortex, which supports self-awareness and metacognition, is among the first regions to suffer under sustained stress and sleep deprivation. Leaders in the grip of fatigue frequently report feeling fine, or at least functional, even as their teams observe obvious signs of degradation.
The observable warning signs are remarkably consistent across contexts: irritability and shortened temper — snapping at team members over minor issues that would normally be handled with patience. Inability to delegate — reclaiming tasks previously assigned to others, driven by a narrowing trust in anyone else's competence. Repetitive checking — reviewing the same information multiple times without retaining it, a direct marker of working memory impairment. Neglect of basic needs — skipping meals, ignoring hydration, dismissing the body's signals as irrelevant to the mission. Rigidity of thought — dismissing team concerns, resisting alternative viewpoints, and becoming locked into a single interpretation of the situation. And loss of narrative coherence — difficulty summarizing the current situation clearly and concisely, a sign that the leader's own mental model has become fragmented.
Because self-detection is unreliable, the solution must be structural rather than individual. The most effective prolonged-crisis organizations build impairment detection into their operating procedures — through mandatory rest protocols, designated "challenger" roles, and decision audit partnerships where a colleague is specifically tasked with monitoring the decision-maker's cognitive state.
[short pause]
Sustainable crisis response requires shift rotation. But shift rotation introduces a problem that is deceptively difficult to solve: INFORMATION CONTINUITY. When a fresh team arrives to relieve an exhausted one, the crisis does not pause to provide a summary. The incoming shift inherits not just a set of facts but an evolving situation with context, nuance, and unspoken assumptions that the outgoing team has absorbed gradually over hours.
Research in emergency medicine demonstrates just how much is lost in transition. A study implementing standardized handover tools in an emergency department found that baseline handover adequacy was only fifty percent — meaning that half the time, critical information was either omitted or poorly communicated during shift changes, as research from 2020 showed. Written communication of handover information was even worse, at just nineteen point two percent. Through structured intervention, these numbers improved dramatically — to eighty-three percent adequacy and sixty-eight point seven percent written communication — but the baseline figures reveal the default state of human handover performance: it is poor.
In crisis contexts, the stakes of handover failure are amplified. The incoming shift commander must not only know what has happened but must understand why specific decisions were made, which assumptions those decisions rested on, and what to watch for that might invalidate those assumptions. This is where Karl Weick's concept of COLLECTIVE SENSEMAKING becomes critically important, as Maitlis and Sonenshein described in 2010. A team's shared understanding of a crisis is not merely a collection of individual facts — it is a collectively constructed narrative that gives those facts meaning, priority, and emotional resonance. When team members rotate through shifts, they carry slightly different versions of this narrative. The incoming team builds a new shared understanding that may diverge subtly but consequentially from the one held by the outgoing team.
[short pause]
The most effective handover protocols share several structural features, derived from both military operations and hospital shift-change research. First, a SITUATION SUMMARY: a concise narrative of where things stand right now — not the full history, but the current operational picture. Second, critical changes: what has changed in the last shift period that the incoming team must know immediately. Third, pending decisions: decisions that are in progress or imminent, including the options under consideration and any deadlines. Fourth, assumptions under strain: explicitly identified assumptions that the outgoing team relied on but that may no longer hold. Fifth, key contacts and relationships: who has been engaged, what they have committed to, and any interpersonal dynamics the incoming team should be aware of. And sixth, watch items: specific indicators or triggers that the incoming team should monitor — the things that, if they change, would require a fundamental reassessment of the current plan.
Notice that this structure goes well beyond "what happened." It transfers not just information but JUDGMENT CONTEXT — the reasoning and assumptions that give information its operational meaning. The goal is not to make the incoming shift as knowledgeable as the outgoing one — that is impossible — but to ensure they know what they need to know to make the next set of decisions well.
[short pause]
There is a persistent myth in crisis leadership that team morale during prolonged operations is sustained through inspirational communication — the speech in the command center, the rallying call, the leader who projects calm confidence. In reality, research on emergency team resilience points to a different set of factors: structural interventions that protect cognitive capacity, maintain social cohesion, and create genuine psychological safety, as Uccheddu and colleagues found in 2025.
[short pause]
How shifts are designed is itself a critical leadership decision, not an administrative detail to be delegated. The evidence on shift length and decision quality is clear: decision fatigue increases as shifts progress, with measurable effects on judgment quality, risk assessment, and error rates, according to research from 2025. Yet crisis organizations routinely default to extended shifts on the assumption that continuity of personnel is more important than freshness of judgment. This assumption deserves scrutiny.
The optimal shift structure for sustained crisis operations balances three competing needs: cognitive freshness — shorter shifts, information continuity — longer shifts to reduce handover frequency, and team cohesion — consistent teams who develop shared mental models. There is no universal answer, but the research suggests that eight to twelve hour operational shifts with structured handover protocols and a mandatory overlap period represent a reasonable compromise for most crisis contexts. Critically, the shift schedule must apply to senior leaders, not just frontline operators. The incident commander who exempts themselves from the rotation "because I need to maintain oversight" is making exactly the kind of fatigued decision that the rotation is designed to prevent.
[short pause]
Rest during prolonged operations is not the absence of work — it is a deliberate operational practice that must be planned, resourced, and enforced with the same rigor as any other element of the response. VanSlyke, Brunell, and Simons emphasized in 2020 that leaders must model rest behavior, visibly stepping away and returning refreshed, to signal that rest is not weakness but professional discipline. This is particularly important in cultures where endurance is valorized and exhaustion is worn as a badge of commitment.
Effective rest protocols include designated rest areas removed from the operational environment, minimum rest periods that are non-negotiable except under predefined escalation conditions, and a clear chain of delegation so that the resting leader knows exactly who holds authority during their absence. The goal is to make rest easy — to remove the friction and anxiety that prevent fatigued people from actually disengaging.
[short pause]
Perhaps the most important structural intervention is the creation of conditions where team members can acknowledge their own limitations without fear. In the Thai cave rescue, one of the most critical moments came when a support diver told the operation's leadership that he did not feel confident performing a particular role in the extraction plan. In many organizational cultures, this admission would have been met with pressure, disappointment, or reassignment to lesser duties. In the Tham Luang operation, it was treated as valuable safety information — the plan was adjusted, another diver was assigned, and the individual was given a different role where his skills were better matched to his current state.
This kind of PSYCHOLOGICAL SAFETY does not emerge spontaneously under crisis pressure. It must be established before the crisis through team norms, rehearsed during training, and actively reinforced during operations by leaders who respond to admissions of limitation with gratitude rather than frustration. As Maitlis and Sonenshein observed in 2010, collective sensemaking in crisis involves shared meanings and emotions — a team that suppresses honest emotional signals is also suppressing the information those signals carry about operational readiness.
[short pause]
Drawing together the concepts in this chapter, we can outline a practical framework for sustaining decision quality across a prolonged crisis. The framework assumes a ninety-six hour — that is, four-day — operational window, long enough to exhaust initial mobilization energy but short enough to plan concretely. For crises lasting weeks or months, the framework is applied in rolling cycles.
Hours zero to twelve: MOBILIZATION. Adrenaline is high, the team is fresh, and decisions are sharp. The critical leadership task in this phase is not making decisions — it is establishing the operational rhythm that will sustain the response when the adrenaline fades. Set the shift schedule. Identify deputies. Establish the handover protocol. Designate rest areas. These investments feel premature when the crisis feels urgent, but they are the most important decisions a leader makes in the first twelve hours.
Hours twelve to thirty-six: THE COMPENSATION PHASE. Fatigue is accumulating but experience is compensating. Pattern recognition remains effective; mental simulation is beginning to degrade. The critical intervention is the first structured handover — getting it right sets the standard for every subsequent transition. Leaders should begin rotating in this phase, not waiting until they feel tired.
Hours thirty-six to seventy-two: THE DEGRADATION ZONE. Decision quality is measurably declining. Risk aversion increases. Teams begin defaulting to established plans even when conditions have changed. The critical intervention is active challenging — designated roles or processes that force reassessment of assumptions. This is also when burnout warning signs become visible in leaders who have not rested adequately.
Hours seventy-two to ninety-six: THE ENDURANCE TEST. Only teams with well-functioning shift rotations, disciplined handovers, and enforced rest protocols maintain effective decision quality in this phase. Teams without these structures experience cascading degradation: poor decisions compound, morale erodes, and the response begins to fragment. The critical leadership task is recognition — acknowledging the strain, celebrating the endurance, and making visible the structural supports that are sustaining the response.
[short pause]
To summarize the key insights from this chapter: Decision quality degrades predictably during prolonged crisis operations, with mental simulation capacity declining before pattern recognition — creating a dangerous gap where leaders feel confident but reason poorly. The indispensability trap prevents leaders from resting because stepping away feels like abandonment; structural interventions such as mandatory rotations, designated deputies, and modeled rest are more reliable than individual willpower.
Shift handovers are high-risk moments for information loss; effective handover protocols transfer not just facts but judgment context — the assumptions, reasoning, and watch items that give facts operational meaning. Collective sensemaking degrades across shift changes as incoming teams construct slightly different shared narratives; overlap periods and structured protocols mitigate but cannot eliminate this drift.
Team resilience during prolonged operations depends on structural pillars: shift design, handover discipline, deliberate rest protocols, and psychological safety — not on motivational communication. And finally, the ability to say "I am not fit to make this decision right now" is among the most important leadership competencies in sustained crisis, and it requires organizational conditions that make such honesty safe.
[short pause]
In Chapter seven, we move from the internal dynamics of the crisis team to the external environment that surrounds it. When a crisis endures, it inevitably becomes public — and the challenge of communicating under uncertainty, managing stakeholder expectations, and maintaining legitimacy while the situation remains unresolved introduces an entirely new set of leadership demands. We will examine how the information environment shapes both the crisis itself and the options available to those responding to it.



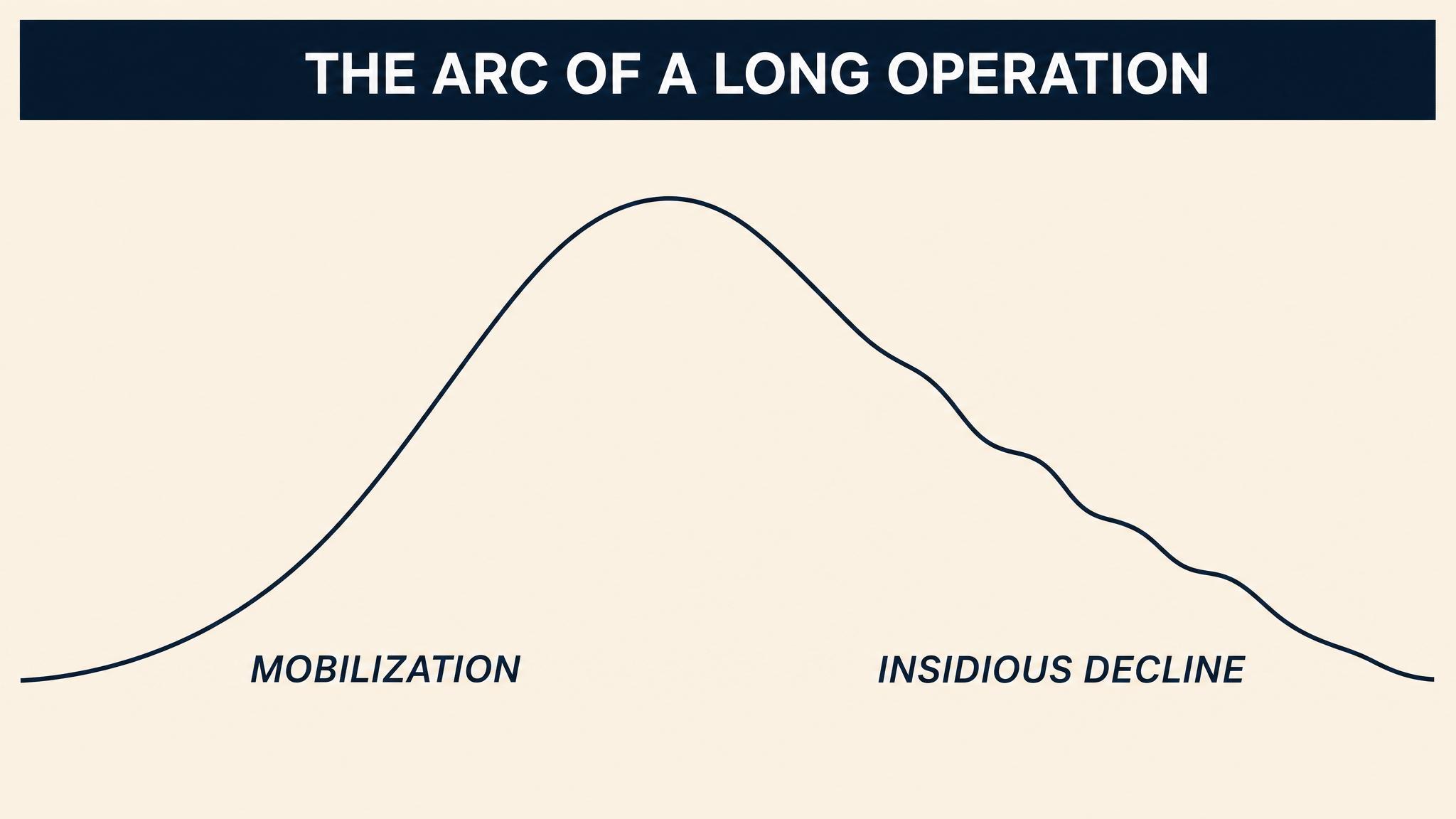








After the Smoke Clears
The crisis is over. The instinct is to move on. That instinct is one of the most damaging things an organisation can do. This chapter examines what happens after the acute phase ends: post-incident review, the…
Would you rather work somewhere that fires people for one mistake or somewhere that never holds anyone accountable?
Would you rather
Group project goes badly. Is it usually because someone didn't pull their weight, or because group projects are just designed to fail?
Group project reality
A coworker makes a mistake that costs the company £10,000. Better response: fire them, or fix whatever system made that mistake possible?
Debate time
Hot take: When people call something 'human error,' they usually mean 'we designed this badly.'
Hot take
You get food poisoning at a restaurant. Who's actually to blame: your server, the cook, the manager, or the system that overworks them all?
Who's responsible?
What's worse: getting blamed for someone else's screwup, or staying quiet while someone else gets blamed for yours?
Tough choice
The Attribution Debate
15 minutesEach team receives a brief incident scenario (e.g., medication error, security breach, production failure). Teams have 5 minutes to prepare arguments for BOTH perspectives: (1) this was primarily a systems failure, and (2) this was primarily individual error. Teams then pair up with another team. Each presents their 'systems failure' argument first (2 min each), then their 'individual error' argument (2 min each). Teams vote on which argument was more compelling and discuss why systems thinking usually reveals more learning opportunities.
Post-Incident Review Hot Seat
20 minutesEach table receives role cards (frontline worker involved, supervisor, safety officer, executive). Using a provided incident scenario, teams conduct a 10-minute mock post-incident review meeting. Each person must stay in character and bring their role's typical concerns and defensive responses. After the roleplay, teams debrief: What questions led to blame? Which questions uncovered system factors? What made people feel safe vs. defensive? Teams share their most effective 'just culture' question with the class.
The Second Victim Gallery Walk
15 minutesTeams receive large paper and markers. They're given 7 minutes to diagram an incident showing: the triggering event, all contributing system factors (policies, training gaps, tech limitations, time pressure, etc.), and where individuals made decisions. Then they draw a circle around 'the second victim' (the staff member who will be blamed) and mark in red all the system factors this person couldn't control. Teams post their diagrams around the room. Half the teams stay to explain their diagram; half circulate as 'consultants' offering feedback on what system factors might be missing. Switch roles after 5 minutes.
Just Culture Decision Tree Build
12 minutesUsing Dekker's framework, each team creates a decision flowchart for determining appropriate organizational response to an incident. Starting from 'An incident occurred,' they map out key questions (Was harm intended? Were rules unclear? Was it human error vs. at-risk behavior vs. reckless behavior?) and corresponding responses (Console, Coach, Discipline, or System Redesign). Teams compare their flowcharts with adjacent tables, identifying differences in their logic. Class discusses which decision points were most contentious and why.
Timeline Reconstruction: Multiple Truths
18 minutesTeams receive the same incident description but from different stakeholder perspectives (night shift vs. day shift, field staff vs. head office, junior vs. senior employee). Each team creates a timeline of 'what went wrong' from their assigned perspective. Teams then present their timelines sequentially. The class observes how different perspectives reveal different 'causes' and how the full system picture only emerges when all views are heard. Instructor facilitates discussion on how incomplete perspective-gathering leads to simplistic attributions.
The Accountability Spectrum
10 minutesDisplay five incident micro-scenarios on the screen simultaneously. Teams have 3 minutes to discuss and position each scenario on a spectrum from 'Pure Systems Failure' to 'Individual Accountability Appropriate' using a shared digital tool or voting cards (1-5 scale). Results are displayed in real-time showing distribution across teams. Instructor reveals where significant disagreement exists, and those tables briefly explain their reasoning. This surfaces how differently people apply just culture principles and common attribution biases. Follow with quick discussion on calibrating organizational responses.
Transcript
On the morning of 14 June 2017, the fire at Grenfell Tower was extinguished. Seventy-two people were dead. Within hours, the questions that would dominate six years of public inquiry began: Who was responsible? Residents pointed to the council. The council pointed to the contractors. The contractors pointed to the manufacturers. The manufacturers pointed to the testing regime. The testing regime pointed to the regulations. And the regulations, it would eventually be shown, had been systematically weakened by government lobbying over decades. Everyone, it seemed, bore some responsibility. And yet, for a very long time, no one bore enough.
[short pause]
This chapter is about what happens after the acute phase of a crisis ends — the period when organisations decide, consciously or not, whether they will actually learn anything. The instinct to move on is powerful. It is also one of the most damaging things an organisation can do. Because the question is never really whether a review will happen. The question is whether the review will produce genuine understanding or a polished document that protects the people who commission it.
[short pause]
There is a predictable rhythm to organisational behaviour after a crisis. First, relief. The immediate threat has passed; the system has survived. Second, exhaustion. The people who led the response are depleted — physically, cognitively, emotionally. Third, a powerful desire to return to normal operations, to close the chapter, to stop being an organisation defined by its worst moment. This desire is entirely human and entirely understandable. It is also the precise point at which most organisations make their most consequential post-crisis mistake.
The pressure to move on is not merely psychological; it is structural. Stakeholders want reassurance. Markets want stability. Media cycles move on. Legal counsel often advises restraint in documenting what went wrong, fearing that candid analysis will become evidence in litigation. The result is a kind of INSTITUTIONAL AMNESIA that masquerades as resilience. We got through it. We're stronger now. Let's look forward, not backward.
But looking backward is precisely how organisations prevent crises from recurring. Research on organisational learning consistently demonstrates that the quality of post-incident analysis is the single strongest predictor of whether an organisation will experience similar failures in the future, as Helmreich found in 2000. Aviation learned this lesson over decades, building what is now the most rigorous learning-from-failure infrastructure of any industry. Most other sectors have not.
[short pause]
When something goes badly wrong, organisations face a fundamental choice — though most do not recognise it as a choice, because the default feels so natural. The default is this: identify the person closest to the failure, determine what they did wrong, punish them, and declare the problem solved. Sidney Dekker calls this the BAD APPLE THEORY — the comforting notion that complex systems are basically safe, and that accidents happen because unreliable people defeat the defences that would otherwise hold, as he described in 2012.
The appeal of this theory is obvious. It provides a clear narrative. It identifies a villain. It implies a simple fix: remove or discipline the villain, and safety is restored. It satisfies the public's desire for accountability. And it protects the organisation's leadership from scrutiny, because if the failure was an individual's mistake, then the system — and the people who designed it — are absolved.
The problem, as Dekker has demonstrated across two decades of research, is that this theory is almost always wrong — and when applied, it is actively dangerous. Punishing individuals for errors that were shaped by systemic conditions does not make the system safer. It makes the system more opaque. Frontline workers learn that reporting errors leads to punishment, so they stop reporting. Near-misses go unrecorded. The systemic conditions that produced the original failure — inadequate training, contradictory procedures, production pressure, poor equipment design — remain untouched, waiting to produce the next incident, as Dekker found in 2008.
[short pause]
There is a well-documented psychological bias at work here. The FUNDAMENTAL ATTRIBUTION ERROR — our tendency to over-attribute others' behaviour to their character rather than their circumstances — is amplified in accident investigation by a second bias: hindsight bias. Once we know that an action led to a bad outcome, it becomes almost impossible to reconstruct the uncertainty that the actor was operating under at the time. Of course they should have noticed the warning signs. Of course they should have followed the procedure. Of course they should have raised the alarm sooner. But "of course" is the language of hindsight, not of the fog-filled, time-pressured, information-poor reality in which decisions were actually made, as Henriksen and Kaplan noted in 2003.
This double bias — attributing to character what should be attributed to context, and judging decisions against information that was not available when those decisions were made — produces investigations that feel thorough but are fundamentally misleading. They answer the wrong question. Instead of asking "Why did this make sense to the people involved, given what they knew at the time?" they ask "Why didn't the people involved do what we now know would have been right?"
[short pause]
Dekker's JUST CULTURE framework offers an alternative to both extremes: the blame-first approach that sacrifices learning for the appearance of accountability, and the no-blame approach that sacrifices accountability for the appearance of learning. A just culture, Dekker argues, recognises that most errors occur within systems that make those errors likely, while also acknowledging that some individual actions do warrant accountability — not because the person is a "bad apple," but because the nature of the action itself crosses a threshold that the profession and the public cannot accept, as he described in 2012.
The framework operates through a series of structured questions. When an individual's actions contributed to an adverse event, investigators ask: Was the action a genuine mistake — an unintentional deviation from safe practice? Was it a slip or lapse — an execution failure where the person intended to do the right thing but failed? Was it an at-risk behaviour — a drift from safe practice that had become normalised within the team or organisation? Or was it a reckless action — a conscious choice to disregard a substantial and unjustifiable risk?
The appropriate response varies accordingly. Mistakes and slips warrant consolation and system redesign. At-risk behaviours require coaching and examination of why the drift became normalised. Only genuinely reckless actions — where the person knowingly and unjustifiably departed from acceptable risk — warrant formal sanction. Crucially, Dekker emphasises that the line between these categories is not self-evident. It is drawn by human beings with their own biases, interests, and political pressures. Who gets to draw that line, and how, is itself a question of justice, as Dekker argued in 2008.
[short pause]
In an earlier chapter, we introduced James Reason's SWISS CHEESE MODEL as a way of understanding how organisational defences work — and how they fail. The model conceptualises safety barriers as slices of Swiss cheese: each is imperfect, with holes representing weaknesses. An accident occurs when the holes in multiple layers align momentarily, allowing a hazard to pass through every defence, as Reason described in 1990.
Applied retrospectively, the model becomes a powerful tool for resisting the temptation of single-cause explanations. The Grenfell Tower inquiry, for instance, ultimately identified failures across at least seven distinct layers: the building's original design, the selection of cladding materials, the role of testing laboratories, the conduct of the refurbishment project, the building control inspection regime, the government's oversight of building regulations, and the fire service's operational response, according to Moore-Bick in 2024. No single failure caused the disaster. The holes aligned.
But the model must be applied carefully. As Wiegmann and Shappell noted in 2019, a common misuse of the Swiss Cheese model is to treat it as a static diagram — a neat retrospective explanation — rather than as a representation of a dynamic system in which holes are constantly opening and closing. Post-incident, there is a dangerous tendency to freeze the model at the moment of failure and treat the alignment of holes as if it were inevitable or obvious. It was neither. The same system had operated for years with many of those holes present, and on thousands of occasions the holes had not aligned. Understanding why they aligned on this particular day, in this particular sequence, is the work of genuine investigation.
[short pause]
Aviation's approach to learning from failure is rightly regarded as the benchmark against which all other industries are measured. The key features are well established: independent investigation bodies with legal authority and no prosecutorial function; mandatory incident reporting; confidential voluntary reporting systems that protect reporters from reprisal; standardised investigation methodologies; and systematic dissemination of findings across the industry, as Helmreich described in 2000.
But even aviation's system is imperfect. Sieberichs and Kluge analysed over two thousand two hundred voluntary incident reports from commercial pilots in 2021 and found significant gaps. Reports involving decision-making errors were far less common than reports involving procedural slips, suggesting that the errors most likely to produce novel system insights are precisely those that pilots are least likely to report. Confidential reporting channels produced richer information about latent failures — the systemic conditions that create the preconditions for error — than mandatory channels, where reporters tended to minimise organisational context. The lesson is sobering: even in the world's most advanced learning-from-failure system, significant learning opportunities are being missed.
[short pause]
The Grenfell Tower inquiry represents a different model — one with exhaustive documentation and substantial public accountability, but where the translation of findings into systemic change has been agonisingly slow. The Phase Two report, published in 2024 — seven years after the fire — identified forty-six specific recommendations embedded in thirty-five paragraphs, targeting failures across government, industry, and regulatory bodies, according to Moore-Bick.
The inquiry demonstrated something important about the politics of post-crisis review: the scope of the investigation determines what it can find. An investigation focused on the fire service's operational response on the night would have identified failures in tactics and communication. The broader inquiry revealed that those operational failures occurred within a system that had been comprehensively degraded by decades of deregulation, corporate dishonesty about product safety, and regulatory capture. The people making decisions on the night were operating inside a system that had already failed them.
[short pause]
The post-incident investigations following the 2011 Fukushima Daiichi nuclear disaster offer a third model. The National Research Council's report in 2014 explicitly acknowledged the challenge of hindsight bias in evaluating the actions of plant personnel who faced overwhelming circumstances. Operators were making life-and-death decisions with failed instrumentation, no electrical power, no lighting, and incomplete understanding of reactor conditions — yet retrospective investigations inevitably evaluated those decisions against knowledge of what was actually happening inside the reactors.
The Fukushima investigations also revealed a pattern common to many large-scale failures: the pre-disaster warnings that were ignored. TEPCO and Japanese regulators had been aware of the risk of large tsunamis. International experience suggested that existing defences were inadequate. But addressing the risk would have required acknowledging that the plant — and the regulatory framework governing it — was less safe than publicly claimed. The cost of that acknowledgment was judged, implicitly, to be too high. This is not an individual failure of judgment; it is a systemic failure of safety culture, in which uncomfortable truths are suppressed because the organisation has no safe mechanism for processing them.
[short pause]
Understanding why reviews matter is necessary but insufficient. Leaders need to know how to actually conduct one. The practical mechanics of post-incident review are more complex than most organisations recognise, and getting them wrong can produce analysis that is worse than useless — analysis that creates false confidence that the problem has been understood when it has not.
The foundation of any serious review is a validated timeline. This sounds straightforward; it is not. Different sources — system logs, witness accounts, communications records, media reports — will frequently contradict each other. Witnesses are particularly unreliable on timing and sequence, not because they are dishonest but because human memory under stress compresses time, reorders events, and fills gaps with plausible inferences that become indistinguishable from actual memories, as Henriksen and Kaplan found in 2003. System logs are more reliable on timing but tell you nothing about what people were thinking, seeing, or deciding. The investigator's task is to triangulate across sources, flag contradictions explicitly rather than resolving them prematurely, and maintain a clear distinction between what is established, what is probable, and what is uncertain.
[short pause]
How you interview people who were involved in the crisis determines the quality of everything that follows. The critical principle is COGNITIVE INTERVIEW TECHNIQUE: ask participants to reconstruct their experience forward in time, from what they knew and saw in the moment, without revealing what you already know about what happened next. The moment an interviewer says "and then the alarm went off" or "at that point the system failed," they have contaminated the participant's recall. The participant's memory will reorganise around the outcome, and you will get a hindsight-saturated narrative rather than a genuine account of how the situation unfolded from their perspective.
The analysis phase must explicitly separate systemic findings — conditions in the organisation's design, culture, resources, or procedures that created the preconditions for failure — from individual performance findings relating to specific decisions and actions. This separation is not about protecting individuals; it is about ensuring that systemic issues are not overlooked because an individual's error is more visible and more satisfying to address. The Swiss Cheese model provides the conceptual architecture: for every active failure at the sharp end, ask what latent conditions at the blunt end made that failure possible, likely, or inevitable, as Reason described in 1990.
The most common failure mode of post-incident review is the production of recommendations that are technically sound but organisationally dead on arrival. Recommendations that require sustained cultural change, significant resource investment, or acknowledgment of leadership failures are routinely adopted in principle and abandoned in practice. Effective reviews anticipate this by specifying not just what should change but who owns the change, what resources are required, what the timeline is, and how implementation will be monitored. Without these specifics, the recommendation is not a plan; it is a wish.
[short pause]
In an earlier chapter, we explored Karl Weick's concept of SENSEMAKING — the process by which people construct meaning from ambiguous or chaotic experience. After a crisis, sensemaking takes on a different character. The ambiguity is, in one sense, resolved: we know what happened. But the meaning of what happened — why it happened, what it reveals, who is responsible, what should change — is constructed through a retrospective narrative process that is deeply political, as Maitlis and Sonenshein demonstrated in 2010.
Organisations construct post-crisis narratives that serve particular functions. A narrative that emphasises individual error serves the function of protecting institutional legitimacy. A narrative that emphasises systemic failure serves the function of driving structural change but may threaten those who built or maintained the system. A narrative that emphasises unforeseeable external factors — the "perfect storm" narrative — serves the function of absolving everyone but often at the cost of learning nothing.
The task for leaders is not to find the "true" narrative — complex crises resist single narratives — but to ensure that the process of narrative construction is honest enough to include uncomfortable truths and inclusive enough to represent the perspectives of those closest to the failure, not just those with the most organisational power. As Maitlis and Sonenshein demonstrated in 2010, the quality of post-crisis sensemaking depends critically on whose voices are heard and whose are silenced.
[short pause]
There is one dimension of post-crisis management that most organisations are catastrophically bad at addressing: the emotional aftermath for the people who were at the centre of the response. Dekker writes powerfully in 2012 about the SECOND VICTIM phenomenon — the professionals whose actions are under scrutiny after an adverse event and who experience trauma, guilt, self-doubt, and isolation, often without any institutional support.
The irony is acute. These are frequently the people who worked hardest during the crisis, who made difficult decisions under impossible conditions, who stayed when others could leave. And in the aftermath, they find themselves the subject of investigation, media scrutiny, and organisational distancing. Colleagues avoid them. The organisation's lawyers advise them not to discuss what happened. They relive the events constantly but have no sanctioned space to process them.
This is not merely a humanitarian concern — though it should be sufficient as one. It is a systemic issue. When organisations fail to support the people involved in adverse events, those people leave. They take their expertise, their institutional knowledge, and their hard-won understanding of how things actually work at the sharp end. They are replaced by people who have not yet learned those lessons. The organisation becomes less safe. And the next generation of frontline workers learns the real lesson of the organisation's response: when things go wrong, you are on your own.
A just culture addresses this directly. It distinguishes between accountability — which may still be appropriate — and abandonment, which never is. It provides psychological support, peer debriefing, and organisational acknowledgment that the person involved is a professional who was operating within a system, not a criminal who defeated it.
[short pause]
The ultimate question of this chapter is not about any single review or any single crisis. It is about whether an organisation can build a culture that learns from failure as a matter of routine — not only after disasters but after near-misses, anomalies, and everyday operational surprises. The research identifies several features that distinguish learning cultures from their opposites:
PSYCHOLOGICAL SAFETY for reporting. People must believe that reporting errors and near-misses will lead to system improvement, not personal punishment. This belief is built through consistent behaviour over time, not through policy statements, as Helmreich found in 2000.
Independence of investigation. Post-incident reviews must be led by people with sufficient independence from the chain of command that produced the failure. Self-investigation is structurally compromised.
Feedback loops that close. Reporting systems that collect data but do not feed visible changes back to reporters will atrophy. People stop reporting when they believe no one is listening, as Sieberichs and Kluge found in 2021.
Tolerance for ambiguity. Learning cultures resist the demand for simple answers and single causes. They are comfortable with findings that identify contributing factors rather than root causes, and with recommendations that address system design rather than individual behaviour.
Leadership modelling. When senior leaders publicly acknowledge their own errors, discuss what they learned, and demonstrate that mistakes are survivable, they create permission for the rest of the organisation to do the same. When they do not, no amount of policy will compensate.
[short pause]
None of these features are technically difficult. All of them are politically difficult. They require leaders to accept that the system they are responsible for is imperfect, that they may have contributed to its imperfections, and that the appearance of control is less valuable than the reality of learning. For many leaders, this is the hardest thing this course will ask of them.
[short pause]
To summarise: The instinct to move on after a crisis is powerful and natural — and it is one of the most damaging things an organisation can do, because it forecloses the learning that prevents recurrence.
The default blame response — find the individual, punish them, declare the problem solved — satisfies the need for accountability but drives error reporting underground and leaves systemic conditions untouched.
Dekker's just culture framework provides a structured alternative that balances accountability with learning, distinguishing between genuine mistakes, normalised at-risk behaviours, and reckless actions.
Hindsight bias is the single greatest threat to honest post-incident analysis — once you know the outcome, it is nearly impossible to reconstruct the uncertainty under which decisions were made.
Effective post-incident reviews require disciplined timeline reconstruction, non-contaminating interview techniques, explicit separation of systemic and individual findings, and actionable recommendations with clear ownership.
Post-crisis narratives are political constructions that serve organisational functions — leaders must ensure the narrative process is honest enough to include uncomfortable truths.
The "second victim" — the professional at the centre of the incident — needs support, not abandonment. Failing to provide this is both unjust and organisationally self-defeating.
Learning cultures are built through psychological safety, independent investigation, closed feedback loops, tolerance for ambiguity, and leadership modelling — features that are technically simple and politically difficult.
[short pause]
In the next chapter, we turn from what organisations learn after a crisis to how they prepare before one. We will examine crisis simulation, scenario planning, and the paradox of preparing for events that are, by definition, surprising. If this chapter has been about the architecture of retrospective learning, the next is about the architecture of prospective readiness — and why the organisations that rehearse failure most seriously are the ones that fail least catastrophically when the real thing arrives.





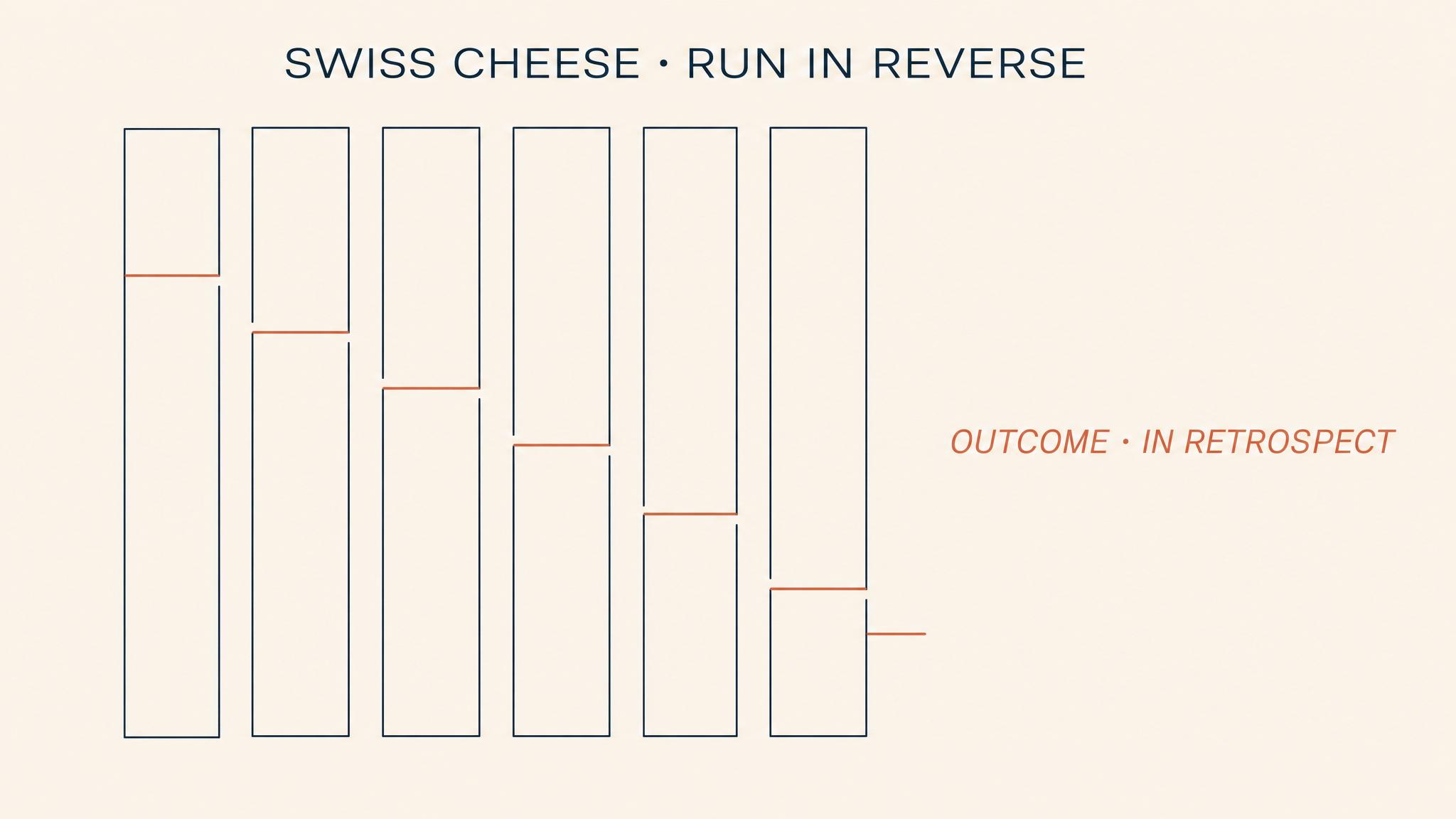







The Crisis Before the Crisis
Every crisis this course has examined was, in a meaningful sense, decided before it began. The Grenfell Tower cladding was installed years before the fire. Fukushima Daiichi's backup generators were placed below the…
Would you rather work somewhere that runs constant disaster drills (annoying but prepared) or somewhere chill that just deals with problems when they happen?
Would you rather
Have you ever caught a mistake before it became a disaster? Did anyone actually thank you, or did they not even notice because nothing went wrong?
Real talk
What's worth more: one employee who's a hero in a crisis, or a whole team that's decent at spotting problems before they blow up?
Debate time
Is constantly thinking about worst-case scenarios smart crisis planning or just workplace anxiety?
Hot take
Your friend never checks the smoke alarm because 'fires basically never happen.' Your other friend tests it monthly. Who's being ridiculous?
Settle this
If something goes wrong anyway, is it worse to fail after months of planning and practice, or to fail because you never bothered preparing?
Quick poll
HRO Principles Under Fire
15 minutesEach table receives a real-world crisis scenario (e.g., hospital emergency, nuclear plant alarm, airline near-miss). Teams have 8 minutes to identify which HRO principles were violated and design ONE immediate intervention. Tables then send a 'spokesperson' to the adjacent table to present their analysis. The receiving table has 2 minutes to challenge or build on the analysis. Instructor facilitates whole-class debrief highlighting patterns.
Vulnerability Assessment Speed Dating
12 minutesTeams are assigned a sector (healthcare, finance, manufacturing, etc.). In 5 minutes, they brainstorm their sector's top 5 hidden vulnerabilities—things most organizations overlook. Then, tables pair up and spend 3 minutes each playing 'vulnerability poker': each team reveals one vulnerability at a time, and the partner team must immediately suggest how to stress-test it. Teams score points for vulnerabilities the other team finds hardest to counter. Debrief focuses on which vulnerabilities were most creative and which stress tests were most practical.
Cascading Crisis Simulation
18 minutesInstructor announces a simple initial crisis event (e.g., 'Your supplier just missed a critical delivery deadline'). Each table has 2 minutes to identify one realistic second-order effect and write it on a card. Cards are passed clockwise. The next table treats that as their new crisis and identifies the NEXT consequence. After 3-4 rounds (8-10 minutes), each table presents their crisis cascade chain. Class votes on which chain represents the most realistic and dangerous escalation path. Debrief focuses on how small failures cascade and why scenario planning must think systemically.
Red Team Assault
15 minutesHalf the tables are 'Blue Teams' (defenders), half are 'Red Teams' (attackers). Blue Teams spend 5 minutes designing a crisis response plan for a given scenario. Red Teams simultaneously brainstorm every way that plan could fail (weak assumptions, communication breakdowns, resource constraints). Tables pair up (one Blue, one Red), and Red Team gets 3 minutes to attack the plan while Blue Team defends and adapts in real-time. Switch roles for round two if time allows. Debrief highlights the value of adversarial thinking in stress testing.
Crisis Culture Diagnostic
12 minutesEach table receives a brief description of a fictional organization's culture (e.g., 'Engineers are rewarded for hitting deadlines, never for raising concerns'). Teams have 6 minutes to diagnose the crisis culture weaknesses and design THREE micro-interventions to shift from individual heroics to organizational preparedness (e.g., changing meeting rituals, reward structures, communication norms). Tables then gallery-walk clockwise, spending 1 minute at each neighboring table's work, adding sticky notes with '+1' for strong ideas or '?' for questions. Instructor synthesizes patterns: What makes crisis culture stick?
Near-Miss Intelligence Contest
10 minutesInstructor presents 3-4 real near-miss case summaries (1-2 sentences each). Each table chooses ONE near-miss and has 5 minutes to extract the maximum learning from it: What was the weak signal? What would a high-reliability organization have done differently? What early warning system could prevent recurrence? Tables score points for insights that other tables didn't identify. Instructor reveals actual lessons-learned from the real incidents. Winning table is whoever got closest to the expert analysis. Debrief emphasizes treating near-misses as intelligence goldmines, not lucky escapes.
Transcript
In the early morning hours of the fourteenth of June, 2017, a small kitchen fire in Flat sixteen of Grenfell Tower ignited the polyethylene-core aluminium composite cladding that had been installed during a refurbishment completed two years earlier. Within minutes, the fire had spread to the exterior of the building. Within hours, seventy-two people were dead. The public inquiry that followed would reveal a cascade of failures in regulation, in procurement, in building management, in emergency response. But the single most consequential decision in the entire Grenfell disaster was not made on the night of the fire. It was made years before, in a meeting room, by people reviewing material specifications and cost estimates, who chose a cladding system that saved roughly two hundred ninety-three thousand pounds over a fire-resistant alternative.
[short pause]
This pattern repeats with eerie consistency across every crisis this course has examined. Fukushima Daiichi's backup generators were placed below the flood line during construction in the nineteen sixties. The organisational culture that delayed the Thai cave rescue's early coordination was built over years of institutional separation between agencies. The communication failures of every case study we have analysed were embedded in systems designed, or neglected, long before the crisis began. This final chapter asks the question that now, after seven chapters of studying how crises unfold, you are equipped to answer: What should have happened before any of it started?
[short pause]
Some organisations operate every day in conditions where a single error could produce catastrophic consequences, and yet they sustain remarkably low rates of failure. Nuclear aircraft carriers launch and recover jet aircraft from a space the size of a few football pitches, in weather that would shut down most airports, with a crew whose average age is nineteen. Air traffic control centres manage thousands of aircraft in close proximity, day after day, with vanishingly rare incidents. Elite surgical teams perform procedures where a millimetre of miscalculation means the difference between recovery and death. These are not organisations that merely respond well to crises. They are organisations structured to prevent crises from occurring, and to contain them rapidly when prevention fails.
As Weick and Sutcliffe described in 2015, these are HIGH-RELIABILITY ORGANIZATIONS, or HROs, and their research reveals something counterintuitive: what distinguishes HROs is not that they are more confident in their safety systems. It is that they are less confident. They operate with a chronic wariness, a suspicion that the next failure is already incubating somewhere in the system and that their current understanding is incomplete. Vogus and Sutcliffe found in 2011 that this represents a dual orientation: HROs pursue both anticipation, identifying and preventing potential problems before they materialise, and containment, developing the capacity to detect and limit problems that have already begun but are not yet catastrophic.
This dual orientation is what separates genuine preparedness from what most organisations actually practice: a confidence-building exercise of writing plans, filing them in binders, and assuming that the existence of the plan constitutes readiness. Jin, Cameron, and Coombs argued in 2024 that traditional preparedness frameworks are insufficient precisely because they focus on artefacts, plans, checklists, resource inventories, rather than on the organisational capacities that determine whether those artefacts will actually function under the cognitive, emotional, and coordinative pressures of a real crisis. They propose CRISIS READINESS as a more demanding concept: a state that includes not just planning but multilevel efficacy, mental adaptability, and what they call "dynamic process-driven agility," the capacity to improvise coherently when the plan meets reality.
[short pause]
Weick, Sutcliffe, and Obstfeld identified in 1999 five processes that characterise how high-reliability organisations maintain this state of alert readiness. Together, these processes constitute COLLECTIVE MINDFULNESS, not a meditative practice, but a quality of organisational attention that enables groups to notice weak signals and respond to them before they amplify into catastrophe.
First, preoccupation with failure. HROs treat near-misses not as evidence that the system works but as evidence that it almost did not. They actively seek out failure signals rather than taking comfort in success.
Second, reluctance to simplify interpretations. When something unexpected occurs, HROs resist the temptation to explain it away with a simple narrative. They maintain nuance, seek additional perspectives, and tolerate ambiguity long enough to develop accurate understanding.
Third, sensitivity to operations. Leaders in HROs maintain close contact with the front line. They know what is actually happening, not just what reports and dashboards say is happening.
Fourth, commitment to resilience. HROs invest in the capacity to detect, contain, and recover from errors that have already occurred. They assume some failures will penetrate their defences and prepare for that eventuality.
And fifth, deference to expertise. In crisis moments, authority migrates to the person with the most relevant expertise, regardless of rank. The organisational hierarchy flexes to match the demands of the situation.
[short pause]
Consider for a moment the five HRO principles against the organisations you have studied in this course. Which principle was most conspicuously absent in the Grenfell Tower case? In Fukushima? In the early hours of the Thai cave rescue? Now apply the same question to your own organisation: which of these five principles is weakest where you work, and what evidence supports your assessment?
[short pause]
Throughout this course, we have used James Reason's Swiss Cheese Model as a retrospective lens, a way to trace how latent conditions and active failures aligned to produce a catastrophic outcome. But the model's greatest practical value lies in its proactive application: systematically examining each layer of defence in your organisation before a crisis, identifying where the holes are, and critically, identifying where holes in adjacent layers might align.
This is the shift from accident investigation to proactive vulnerability assessment. Instead of asking "what failed?" after a disaster, you ask "what could fail?" while there is still time to intervene. The method is deceptively simple: enumerate your layers of defence, governance, plans, training, culture, resources, examine the integrity of each layer, and look for the dangerous alignments, the places where a weakness in one layer is not compensated by strength in an adjacent one.
The difficulty, of course, is that organisations are systematically biased against seeing their own vulnerabilities. According to Haas, Kulbacki, and McGuire in 2020, near-miss reporting systems, one of the most powerful tools for surfacing latent weaknesses, function effectively only when workers have genuine decision-making autonomy, when they are involved in analysing the events they report, and when the organisational response to reports is visibly constructive. Reporting systems that merely collect data without feeding it back into decision-making are, in effect, a defence layer with a hole in it.
[short pause]
If vulnerability assessment identifies where your defences are weak, stress testing reveals how those weaknesses will behave under pressure. As Younis described in 2024, there are two complementary approaches: stress testing, which applies extreme but plausible conditions to see where systems break, and scenario analysis, which envisions a range of possible futures to test the breadth of organisational response capacity. Both are necessary. Stress testing without scenario breadth will prepare you very well for the last crisis you experienced. Scenario analysis without stress intensity will surface problems in theory that never get tested in practice.
Most organisational exercises fail on one or both dimensions. They test only the most obvious scenarios, the ones everyone expects and has rehearsed. They allow leaders to perform well because the exercise is designed to confirm existing plans rather than challenge them. They run for a few hours rather than the days or weeks a real crisis demands. They skip the parts that are genuinely difficult: the moment when two stakeholders want contradictory things, when the information arriving is ambiguous and potentially wrong, when the team has been operating for sixteen hours and is exhausted.
Effective stress tests are built on the understanding developed across this entire course. They incorporate activation threshold ambiguity from Chapter two, because real crises do not announce themselves clearly. They create genuine cognitive load from Chapter three, because decisions under pressure are qualitatively different from decisions in a meeting room. They embed stakeholder conflicts from Chapter four and require communication under uncertainty from Chapter five, because the social dynamics of crisis are at least as challenging as the operational ones. They run long enough to test fatigue and decision degradation from Chapter six, and they include post-exercise review processes designed to surface real learning from Chapter seven.
[short pause]
Recall for a moment the last crisis exercise or drill you participated in at work. Was it genuinely challenging, or did it primarily confirm that existing plans would work? Did it test your decisions under cognitive load, or did it allow careful, unhurried deliberation that would be impossible in a real crisis? What would you change about it now?
[short pause]
These tools, vulnerability assessment and stress testing, are necessary but insufficient. An organisation can complete a vulnerability scan, design excellent exercises, and still fail in crisis if these activities remain isolated projects rather than expressions of an embedded organisational culture. As Vogus and Sutcliffe noted in 2016, there's a critical distinction between crisis-as-event thinking, which treats crises as discrete occurrences to be managed, and crisis-as-process thinking, which understands crises as emerging from ongoing organisational dynamics. Preparedness, in this view, is not something you do periodically. It is something you are, continuously.
Hanssen, Meidell, and Lindøe reinforced this point in their 2022 systematic review of organisational resilience and learning. They find that resilient organisations learn not only from crisis but in crisis and for crisis, that is, they develop learning systems that operate before, during, and after disruptive events. Critically, they find that learning from normal functioning and minor events is as important as learning from major incidents. This aligns directly with the HRO principle of preoccupation with failure: it is the organisations that treat everyday anomalies as data, not noise, that build the deepest reserves of adaptive capacity.
This is where the concept of crisis readiness becomes essential. Readiness is not a checklist state. It is a dynamic condition that encompasses multilevel efficacy, confidence at individual, team, and organisational levels, mental adaptability, the capacity to revise mental models rapidly, and emotional leadership, the ability to manage the affective dimensions of crisis response. Training and plans contribute to readiness, but they do not constitute it. An organisation can have excellent plans and well-trained individuals and still lack readiness if those plans have never been tested under realistic conditions, if the individuals have never worked together under genuine pressure, or if the organisational culture punishes the kind of honest reporting that surfaces problems before they escalate.
[short pause]
Organisational preparedness is not a binary state. You are not either ready or unready. It exists on a continuum, and understanding where your organisation sits on that continuum is essential for knowing what interventions will actually make a difference. An organisation at the very beginning of its preparedness journey needs different things than one that has strong plans but weak culture, or one that exercises regularly but fails to learn from what the exercises reveal.
A useful framework maps five levels of preparedness: reactive, aware, prepared, adaptive, and resilient, across six organisational dimensions. Each level is defined by observable behaviours, not aspirational statements. The goal is not to reach the top of every dimension. For most organisations, that would require resources they do not have. The goal is to understand your current state honestly, identify the highest-value improvements, and build a realistic pathway toward greater readiness.
[short pause]
This chapter, and this course, has traced an arc from the moment a crisis is first recognised through the decisions, communications, and coordinating structures that shape the response, through the review processes that determine whether the organisation learns from its experience, and finally to the preparedness practices that determine whether the next crisis will unfold differently. But that arc is misleading in one important respect: it implies a sequence. In reality, every element operates simultaneously. The organisation that is responding to today's crisis is also, whether it knows it or not, shaping its readiness for the next one.
The frameworks you have studied in this course are not academic abstractions. Reason's Swiss Cheese Model is a tool you can use tomorrow morning to examine the defence layers in your own organisation. Klein's Recognition-Primed Decision model tells you exactly what kind of training your people need: not rule memorisation, but pattern library development through realistic scenario exposure. Weick's sensemaking framework specifies what your communication systems must do under stress: maintain shared situational awareness through continuous information exchange, not periodic briefings. Dekker's just culture framework tells you what must be true about your reporting systems if you want near-misses to surface before they become catastrophes. And Boin and colleagues' crisis leadership model tells you what governance arrangements must be in place, and tested, before the crisis calls for them.
[short pause]
The most important lesson of this course may be the simplest: every crisis is decided before it begins. The cladding is already on the building. The generators are already below the flood line. The reporting culture already does, or does not, surface the warnings. The leaders have already been trained, or they have not. The question is not whether your organisation will face a crisis. The question is what kind of organisation it will be when the crisis arrives.
As a Chinese proverb frequently cited in emergency management literature reminds us: "The best time to plant a tree was twenty years ago. The second best time is now."
[short pause]
You now have the conceptual tools to answer that question, and to change the answer. The work of preparedness is never finished, because the threats evolve, the organisation changes, people turn over, and the comfortable assumption that "it won't happen here" creeps back in the moment you stop actively resisting it. High-reliability organisations understand this. They know that safety is not a state you achieve. It is a condition you maintain through continuous, deliberate, often uncomfortable attention to the possibility that you might be wrong about what you think you know.
[short pause]
If a major crisis struck your organisation tomorrow, what is the single decision already made, a policy adopted, a system designed, a capability neglected, that would most shape the outcome? What would it take to change that decision now, while there is still time?
[short pause]
Let's bring these ideas together. High-reliability organisations distinguish themselves not through confidence in their systems but through chronic wariness and collective mindfulness, five principles that keep organisational attention tuned to weak signals of emerging failure. Proactive vulnerability assessment applies the Swiss Cheese Model forward rather than backward, identifying where defence layers are weak and, critically, where weaknesses in multiple layers align to create compound failure paths.
Effective crisis exercises must create the conditions that make real crises difficult: cognitive load, ambiguity, time pressure, stakeholder conflict, fatigue, and novel scenarios that cannot be solved by following the existing plan. Near-miss reporting systems are among the most powerful preparedness tools available, but only when workers have autonomy, are involved in analysis, and see visible organisational responses to their reports.
Crisis readiness is a dynamic condition encompassing multilevel efficacy, mental adaptability, and emotional leadership. Training and plans contribute to readiness but do not constitute it. Organisational resilience depends on learning not only from crises but from normal operations and minor events. The organisations that treat everyday anomalies as data build the deepest adaptive capacity. And every major framework in this course, Reason, Klein, Weick, Dekker, Boin, can be applied proactively to design systems, training, cultures, and governance structures that shape crisis outcomes before crises begin.
[short pause]
You began this course learning to recognise crises. You studied how leaders decide under pressure, how communication shapes collective action, how teams coordinate and fragment, how fatigue and stress degrade performance, and how organisations succeed or fail at learning from their experiences. In this final chapter, you reversed the entire arc, applying everything you have learned to the question of what should happen before the crisis starts. Carry these frameworks forward. The organisations you lead, the systems you design, and the cultures you shape will determine how the next crisis unfolds, not on the day it arrives, but in the months and years before it. That work begins now.